飽和計画(saturated design)とは、実験回数と、モデルに含まれた項の個数が等しい計画を指します。過飽和計画は、名前からわかるとおり、モデル項の個数が実験回数より多い計画を指します(Lin, 1993)。過飽和計画を使えば、何十個もの因子をその半分以下の実験回数で検討することができます。調べたい因子の数は多いのに、1つの実験に膨大な費用がかかってしまう状況で、因子のスクリーニングを行いたい場合に過飽和計画は役立ちます。
|
•
|
有効な因子(active factor; 実際に応答に対して影響をもつ因子)の個数が実験回数の半分以上である場合、それらの因子の影響を検出できなくなる可能性が高くなります。一般に、実験回数は、有効な因子の個数の4倍以上である必要があります。つまり、有効な因子が5つあると考えられるときは、少なくとも20回の実験が必要です。
|
|
•
|
過飽和計画のデータを自動的に処理する統計分析は、まだ考案されていません。JMPでは、変数増加法によるステップワイズ回帰を使えば、ある程度、穏当な統計分析ができます。また、「スクリーニング」プラットフォーム([分析]>[発展的なモデル]>[発展的な実験計画モデル]>[2水準スクリーニングのあてはめ])を使えば、より合理的な枠組みで簡単に分析できます。
|
メモ: ここで取り上げている例は、過飽和計画を説明するためだけのものです。どのような過飽和計画でも、実験回数は14回以上にすべきです。また、この例では有効な因子が4つ以上ある場合には、8回だけの実験で実験結果を解釈することは非常に難しいです。第 “過飽和計画の制約”を参照してください。
|
1.
|
[実験計画(DOE)]>[カスタム計画]を選択します。
|
|
2.
|
「N個の因子を追加」の右側のボックスに「12」と入力します。
|
|
3.
|
[因子の追加]>[連続変数]を選択します。
|
|
4.
|
[続行]をクリックします。
|
|
6.
|
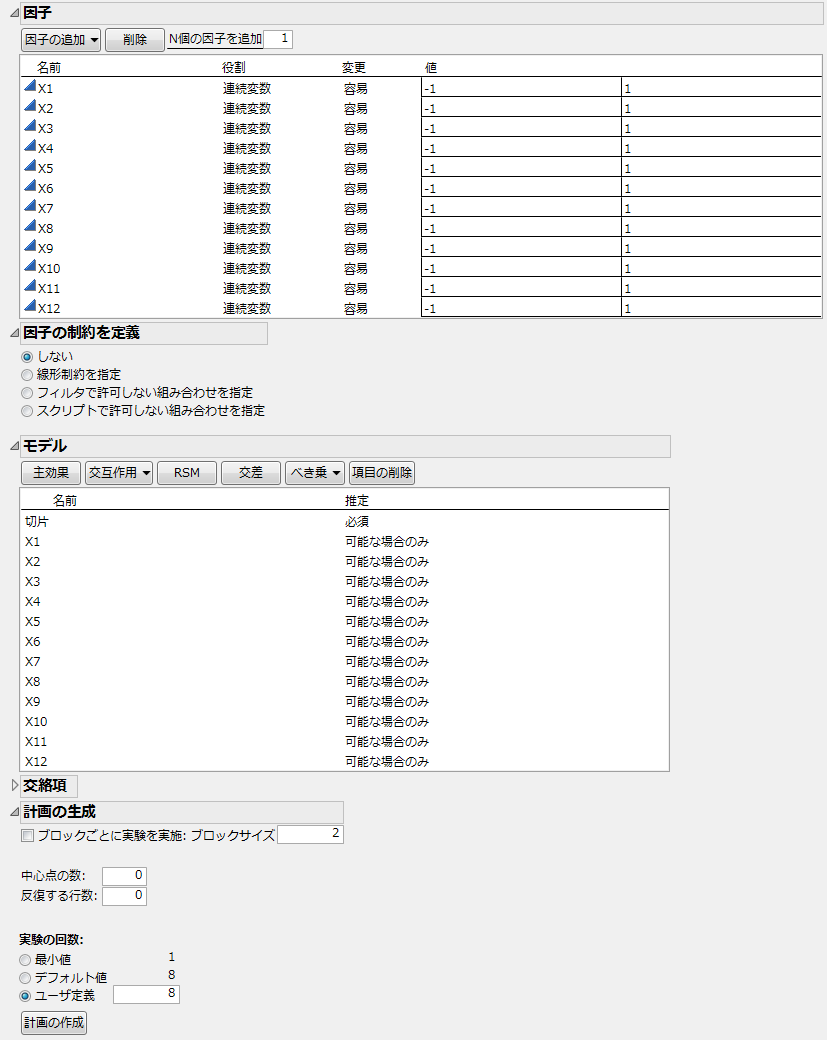
いくつかのモデル効果を[可能な場合のみ]に設定すると、Bayes流のD-最適化基準が使われるようになります。
図5.12 因子、モデル、実験の回数
|
7.
|
「交絡項」アウトラインで、すべての項を選択して[項目の削除]をクリックします。
|
|
8.
|
赤い三角ボタンのメニューから[応答のシミュレート]を選択します。
|
|
9.
|
|
10.
|
|
11.
|
[計画の作成]をクリックします。
|
|
12.
|
[テーブルの作成]をクリックします。
|
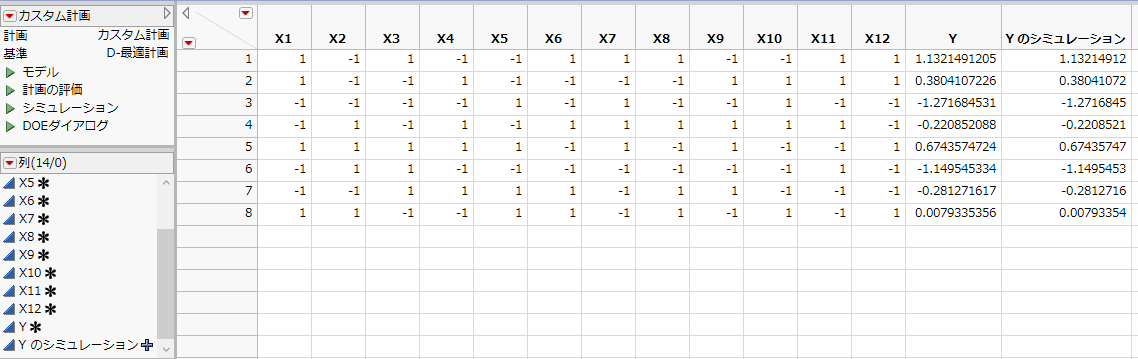
応答列の「Y」と「Y のシミュレーション」は、最初は同じシミュレーション値になっています。この例の応答値は、N(0, s) に従う乱数です。 ここで、sは、デフォルトでは1になっています。「検出力分析」アウトラインにおける「RMSEの予想値」で指定されている値がデフォルトでは使われます。「Yのシミュレーション」の値は、「応答をシミュレート」ウィンドウのパラメータ値によって定義されたモデルを使い、ランダムに生成されます。「Y」列には、実験を実行した後に、その実験で得られた値を入力してください。
図5.14 「応答をシミュレート」ウィンドウ
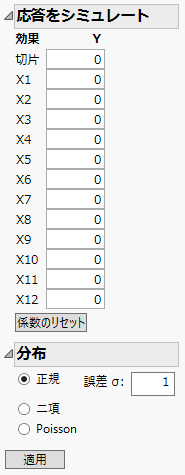
「応答をシミュレート」ウィンドウには、すべての項の係数が0、選択された分布が[正規]、「誤差σ」が1と表示されています。「Y」列と「Yのシミュレーション」の値は、現在、ランダムな誤差だけを反映しています。モデル係数は、すべての係数が推定可能になっていないので、デフォルトでは0に設定されています。
|
13.
|
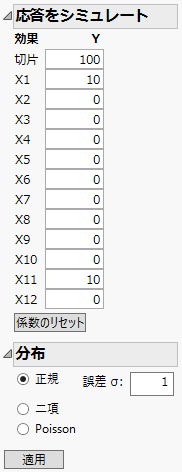
図5.15 「応答をシミュレート」のパラメータ値
|
14.
|
[適用]をクリックします。
|
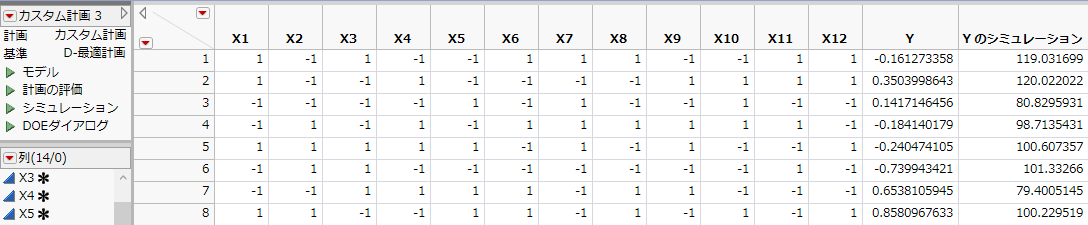
今回のシミュレーションでは、「X1」と「X11」を、誤差の標準偏差よりもかなり大きな効果を持つ因子として指定しました。次節では、統計分析によって、これら2つの因子を有意な因子として識別できるかどうかを確認していきます。
「スクリーニング」プラットフォームは、有効な因子(実際に応答に影響している因子)を識別する1つの方法を提供しています。X1とX11が有効な因子の場合の「Yのシミュレーション」列の計画データテーブルには、3つのスクリプトが含まれています。「スクリーニング」スクリプトは、「スクリーニング」プラットフォーム([分析]>[発展的なモデル]>[発展的な実験計画モデル]>[2水準スクリーニングのあてはめ])を使ってデータを分析します。
|
1.
|
計画のデータテーブルの「テーブル」パネルで、「スクリーニング」スクリプトの横にある緑の三角ボタンをクリックします。
|
図5.17 過飽和実験計画の「スクリーニング」レポート
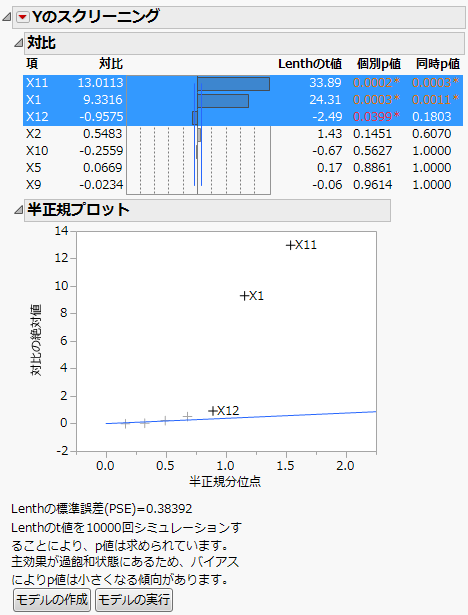
因子「X1」と「X11」の「対比」と「Lenthのt値」の値は大きく、 「同時p値」の値は小さくなっています。「半正規プロット」内では、「X1」も「X11」も直線からかなり離れています。これらの「対比」レポートと「半正規プロット」レポートから、「X1」と「X11」が重要であることがわかります。「X12」の「個別のp値」は0.05以下ですが、その効果は「X1」や「X11」に比べてずっと小さいことがわかります。
この計画は過飽和なので、この計画におけるp値は、すべての効果が推定可能となっている計画におけるp値よりも、小さくなっているかもしれません。なぜなら、過飽和計画では、ある効果の推定値は、応答に影響している他の効果によってバイアスをもつようになっているからです。過飽和実験計画の「スクリーニング」レポートに示すように、[モデルの作成]ボタンの上に、その可能性を説明する注釈が表示されます。
さらに、問題としている効果が、他の効果と高い相関関係にあるかどうかも確認したほうが良いでしょう。相関が高い場合、一方の効果が他方の効果がもつ有意性を隠してしまう場合があります。「相関のカラーマップ」アウトラインのカラーマップには、効果間における相関係数の絶対値が表示されます。
|
2.
|
[モデルの作成]をクリックします。
|
|
3.
|
「モデルの指定」ウィンドウで[実行]をクリックします。
|
図5.18 モデルのパラメータ推定値
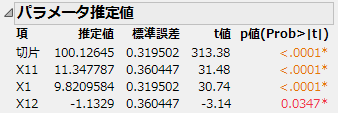
「X11」と「X1」のパラメータ推定値は、モデルをシミュレートするのに使用した理論上の値に近いものとなっています。「X1」と「X11」に「10」と指定した「応答をシミュレート」のパラメータ値を参照してください。因子「X12」の有意性は偽陽性の例です。
|
4.
|
「カスタム計画」ウィンドウで、「計画の評価」>「相関のカラーマップ」アウトラインを開きます。
|
図5.19 「相関のカラーマップ」アウトライン
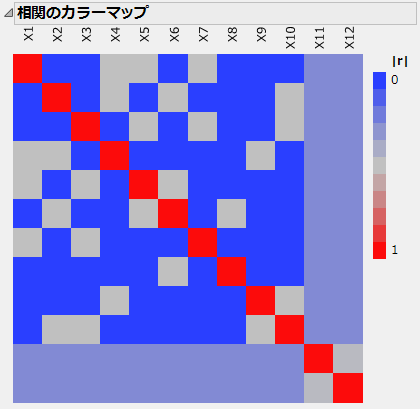
セルの上にカーソルを置くと、相関の絶対値が表示されます。「X1」は、他の主効果(「X4」、「X5」、「X7」)と0.5という高い相関があります。(「相関のカラーマップ」アウトラインは、JMPのデフォルトの色を使用しています。)
ステップワイズ回帰を使っても、重要な因子を識別できます。X1とX11が有効な因子の場合の「Yのシミュレーション」列の計画テーブルには、3つのスクリプトが含まれています。「モデル」スクリプトで呼び出される「モデルのあてはめ」プラットフォームで、ステップワイズ回帰を使用してデータを分析しましょう。
|
1.
|
計画テーブルの「テーブル」パネルで、「モデル」スクリプトの横にある緑の三角ボタンをクリックします。
|
|
2.
|
|
3.
|
[実行]をクリックします。
|
|
4.
|
|
5.
|
[実行]をクリックします。
|
図5.20 過飽和計画のステップワイズ回帰
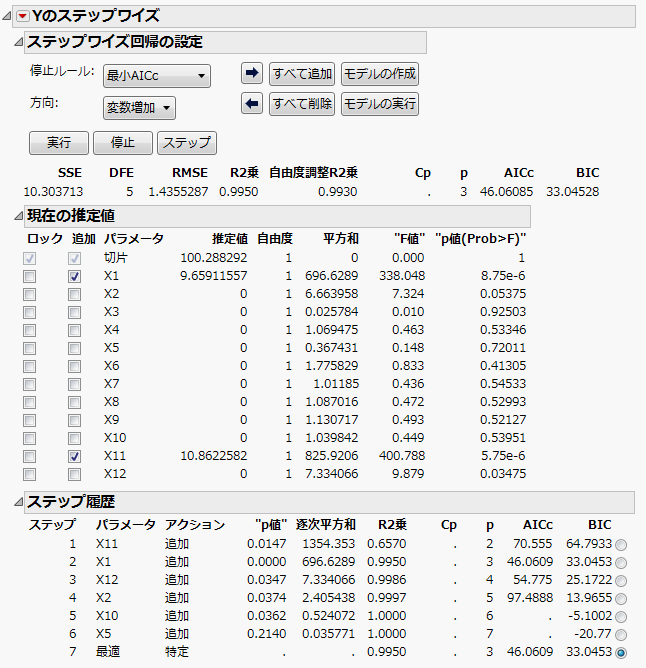
過飽和計画のステップワイズ回帰は、選択したモデルで、2つの重要な因子「X1」と「X11」で構成されています。一番下には「ステップ履歴」が表示されます。「X1」と「X11」とその他の因子の相関によって、他の因子の有意性が隠されている可能性があることも気を付けてください。「相関のカラーマップ」アウトラインを参照してください。