それぞれの対比のt値は、対比をPSEで割った値です。帰無仮説のもとでのこれらのt値の確率分布を求めることは困難なので、 乱数シミュレーションによって求めています。以下で説明する方法は、Ye and Hamada(2000)の議論に基づいています。
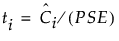
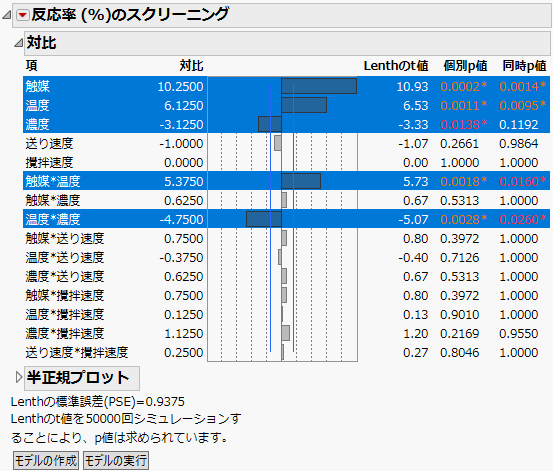
スクリーニング計画で最も重要なのは、個別の過誤率(individual error rate)です。「個別の過誤率」とは、ある1つの効果において、その効果が影響をもたないのに、誤って影響をもつと判定してしまう確率です。この個別p値は、i番目の効果1つに関して、帰無仮説のもとで|ti|以上となる確率です。
「2水準スクリーニングのあてはめ」プラットフォームでは、比較的多くの効果を一度に検定するため、実験全体の過誤率(experimentwise error rate)も重要です。「実験全体の過誤率」とは、複数の効果が実際には影響がないのに、そのうちの少なくとも1つの効果を影響があると誤って判定してしまう確率です。そのような多重性を考慮した同時p値は、i番目の効果に対して、帰無仮説のもとでmax|ti|以上となる確率です。
「2水準スクリーニングのあてはめ」プラットフォームは、モンテカルロ乱数シミュレーションによって、これらの検定統計量の分布を生成し、p値を求めています。そのシミュレーションでは、まず、平均が0、標準偏差がPSEに等しいn - 1個の正規乱数を生成します。この正規乱数は、応答に影響している効果がまったくないという帰無仮説のもとでの、実験で得られる対比の値を表しています。このようなn-1個のランダムな対比の値の組が、全部で10,000セット生成されます。
i番目における対比の個別p値を考えてみましょう。 10,000*(n - 1) 個の乱数から、Lenthのt値が生成されます。個別p値は、それらのt値の絶対値のうち、データから得られた対比以上となっているものの割合です。つまり、個別p値は、シミュレーションで得た10,000*(n - 1)個のt値の絶対値を降順に並べた中で、観測したLenthのt値の絶対値が位置する位置です。この個別p値は、帰無仮説のもとでの分布において、観測されたLenthのt値の絶対値より右側に位置する領域を近似したものです。
「実験全体の過誤」とは、応答に影響していない効果が複数ある場合に、そのうちの少なくとも1つを、t値に基づいて帰無仮説を棄却してしまうことを指します。この過誤率に対応したp値を求めるには、t値の絶対値の最大値(max|ti|)の分布をまず求めなければいけません。
この分布を求めるのに、10,000回の各シミュレーションで、t値の絶対値の最大値を求めます。こうして求められた10,000個の最大値が、帰無仮説のもとでの検定統計量の分布を形成します。同時p値は、シミュレーションで得た10,000個のt値の絶対値の最大値を降順に並べた中で、観測したLenthのt値の絶対値が位置する位置です。この同時p値は、帰無仮説のもとでの分布において、観測されたLenthのt値の絶対値の最大値より右側に位置する領域を近似したものです。
シミュレーションのデフォルトにおける回数を10,000回から変更するには、LenthSimNという名前のグローバルなJSL変数に値を割り当てる必要があります。p値の計算に使用したシミュレーションの回数は、レポートウィンドウに表示されます。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Reactor Half Fraction.jmp」を開きます。
|
|
3.
|
「反応率(%)」を選択し、[Y]をクリックします。
|
|
4.
|
|
5.
|
「反応率(%)のスクリーニング」の赤い三角ボタンをクリックして、[スクリプトの保存]>[スクリプトウィンドウへ]を選択します。
|
|
6.
|
スクリプトの1行目に「LenthSimN=50000;」を挿入します。
|
LenthSimN=50000;
Fit Two Level Screening(
Y( :Name("反応率(%)")),
X( :Name("送り速度"), :Name("触媒"), :Name("攪拌速度"), :Name("温度"), :Name("濃度"))
);
|
7.
|
スクリプトウィンドウ内で右クリックし、[スクリプトの実行]を選択します。
|