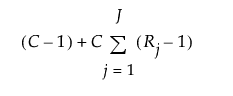ここでは、「潜在クラス分析」プラットフォームであてはめられる潜在クラスモデルについて説明します。潜在クラスモデルの詳細については、Collins and Lanza(2010)およびAgresti(2013)を参照してください。
これらJ変数から構成されるベクトルには、全部でW = R1*...*RJ個のパターンがあります。ある回答者の応答は、これらJ変数に対する応答値によって定義されます。この応答値は、y = (y1, ..., yj)という長さJの行ベクトルで表されます。いま、Yを、W個の応答パターンを回答者に関して縦に並べた、W x Jの行列とします。そして、Yの各要素でパターンがywとなる確率をPr(yw)と表します。この確率の全パターンでの合計は1となります。
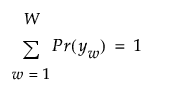
|
•
|
Cを、潜在クラスモデル内のクラスターの数とします。
|
|
•
|
|
•
|
|
•
|
ρj,k|cを、クラスcに属するという条件のもとで、列jの応答がrj,kになる確率とします。(つまり、ρj,k|cは項目応答の確率です。)クラスターcと応答変数jの各組み合わせ内において、ρj,k|cを合計したものは1となります。
|
|
•
|
潜在クラスモデルでは、特定の応答ベクトルy = (y1, ..., yj)が観測される確率が、各潜在クラスCにおいて、応答変数ごとに独立に条件付き確率を掛け合わせ、それらを合計したものと仮定されています。
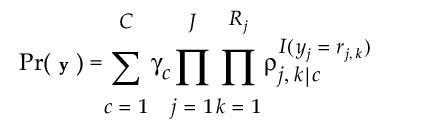
この式は、「潜在クラス分析」の赤い三角ボタンから[混合計算式とクラスター計算式の保存]オプションを選択すると保存される「確率計算式 クラスター」の分母となります。一方、「確率計算式 クラスター」は、Pr(クラスター = c | y)であり、この条件付き確率はPr(y, クラスター = c) / Pr(y)で計算されます。
潜在クラスモデルのこれらのパラメータ(γおよびρ)は、反復法の一種であるEM(Expectation-Maximization)法を用いて推定されます。なお、潜在クラスモデルでは、次式により計算される個数だけのパラメータを推定します。