クラスターを色分けする凡例とともに、データの主成分のうち最初の2次元を軸にして点とクラスターをプロットします。円はクラスターの中心の周囲に描かれ、円の大きさは各クラスターの度数に比例します。陰影が付けられた領域は、平均を中心とした密度の等高線です。デフォルトでは、各クラスターにおいて90%が含まれる領域を示しています(Mardia et al. 1980)。プロットの下のリストを使用すれば、第1主成分と第2主成分以外をプロットすることができます。また、矢印ボタンによって、可能な軸の組み合わせをすべて繰り返して表示することもできます。プロットの下には、クラスターの色をデータテーブルに保存するオプションもあります。詳細については、第 “色をテーブルに保存”を参照してください。固有値は降順に表示されています。
クラスターごとにパラレルプロットを作成します。オプションで、プロットにおけるデータや平均の表示/非表示を切り替えることができます。詳細については、『グラフ機能』の「パラレルプロット」章を参照してください。
各行に割り振られたクラスターの番号を含む「クラスター」という名前の列を、データテーブルに追加します。正規混合分布法の場合、所属する確率の最も高いクラスターが保存されます。
「クラスター計算式」という計算式列をデータテーブルに追加します。この計算式は、どのクラスターに属するかを求めるものになっています。
クラスターごとに「確率クラスター<k>」という名前の列を追加して、オブザベーションがそのクラスターに属する確率を保存します。
距離を合計したものを計算する計算式の列。この列の計算式は、[密度関数の保存]オプションによって作成される「混合密度」列の計算式と同じです。
オブザベーションがクラスター<k>に属する確率。これらの列には、[混合確率の保存]オプションによって作成される「確率クラスター<k>」列と同じ値を求める計算式が保存されます。混合確率を計算する計算式は次のとおりです。
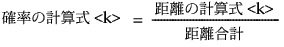
正規混合分布の密度関数の推定値を含む「混合密度」という列を、データテーブルに追加します。