「Boston Housing.jmp」サンプルデータには、住宅価格の中央値に影響を及ぼしていると考えられる13の因子に関するデータが記録されています。ここでは、ニューラルネットワークを使用してモデルをあてはめてみます。ニューラルネットワークの場合、通常の回帰分析で行われているような仮説検定によっては、各因子の重要度を評価できません。そこで、ここでは[変数重要度の評価]オプションを使用してみます。
処理の一部で乱数を用いているため、実際の結果は、以下と違ったものになりますが、おおむね同じになるはずです。この例では、乱数を用いている処理が2個所あります。第1に、ニューラルネットワークをあてはめる際に、k分割交差検証を用います。この時、学習データと検証データに無作為に元のデータが分割されます。第2に、因子重要度の計算で、無作為に抽出した標本を使います。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Boston Housing.jmp」を開きます。
|
|
2.
|
[分析]>[予測モデル]>[ニューラル]を選択します。
|
|
3.
|
|
4.
|
「列の選択」リストで他のすべての列を選択し、[X, 説明変数]をクリックします。
|
|
5.
|
[OK]をクリックします。
|
|
6.
|
「ニューラル」の「モデルの設定」パネルで、「検証法」の下のリストから[K分割]を選択します。
|
|
8.
|
[実行]をクリックします。
|
|
9.
|
「モデル NTanH(3)」レポートの赤い三角ボタンをクリックし、[プロファイル]を選択します。
|
|
10.
|
「予測プロファイル」の横にある赤い三角ボタンのメニューから[変数重要度の評価]>[従属する標本再抽出の入力]を選択します。
|
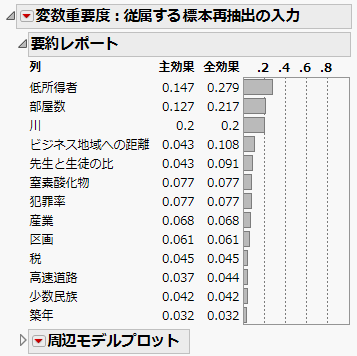
「変数重要度: 従属する標本再抽出の入力」レポートが表示されます(「従属する標本再抽出の入力」レポート)。「予測プロファイル」のセルの並び順が、レポートの「全効果」の値の大きい順に変化している点を確認してください。「従属する標本再抽出の入力」レポートの「全効果」の値から、「部屋数」と「低所得者」が応答の予測値に大きい影響力を持つ因子だと判断できます。
図3.26 「従属する標本再抽出の入力」レポート
|
11.
|
「予測プロファイル」の横にある赤い三角ボタンのメニューから[変数重要度の評価]>[独立な標本再抽出の入力]を選択します。
|
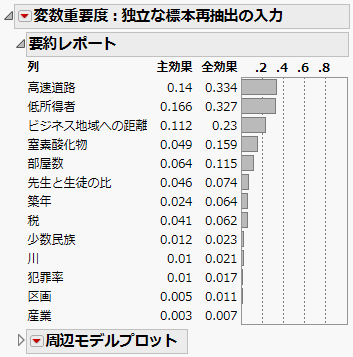
因子間の相関がなく、分布が一様分布でない場合には、この[独立な標本再抽出の入力]オプションを用いるのが良いでしょう。「変数重要度: 独立な標本再抽出の入力」レポートを「独立な標本再抽出の入力」レポートに示します。ここでも、予測値に対する寄与率の高い因子として「高速道路」と「低所得者」の2因子を確認できます。
図3.27 「独立な標本再抽出の入力」レポート