 カテゴリカルな応答変数に対するK近傍法の例
カテゴリカルな応答変数に対するK近傍法の例|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Equity.jmp」を開きます。
|
|
2.
|
[分析]>[予測モデル]>[K近傍法]を選択します。
|
|
3.
|
「BAD」を選択し、[Y, 目的変数]をクリックします。
|
|
4.
|
説明変数の1つである「DEBTINC」は、欠測値が多いです。ここではモデルに含めないことにします。なお、連続尺度の説明変数における欠測値は、その説明変数の平均によって補完されます。このような補完は、場合によっては妥当な方法ではありません。DEBINCの欠測値が多いのですが、このような欠測値が多い変数を分析に加えたほうが、予測精度が上がる場合もあります。しかし、この例では分析に使いません。
|
5.
|
「Validation」列を選択し、[検証]ボタンをクリックします。
|
|
6.
|
[OK]をクリックします。
|
図8.2 「K近傍法」レポート
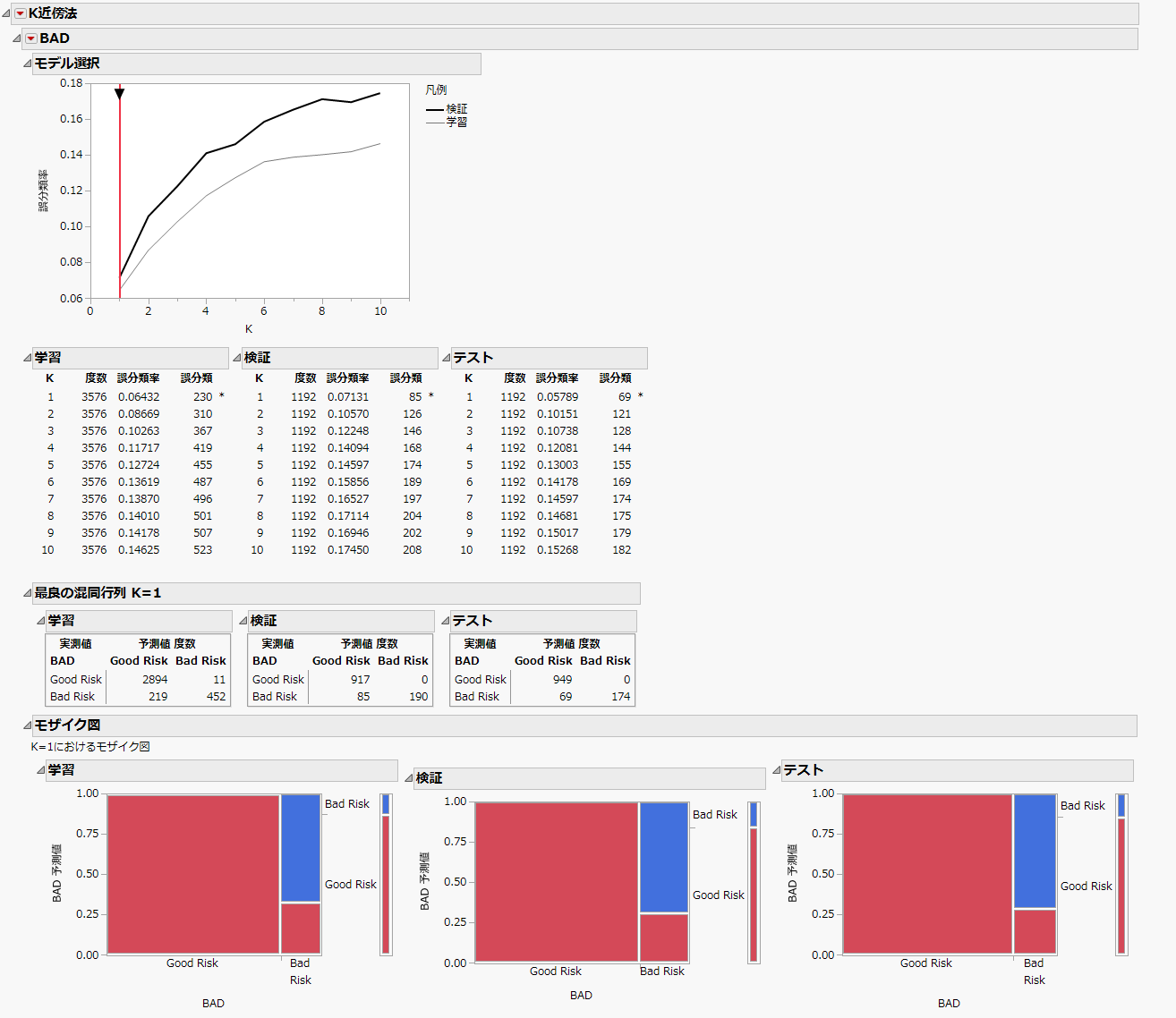
JMPは、学習セットのオブザベーションだけを使用して、Kの値ごとにモデルをします。そして、その作成された各モデルに対して、検証セットのデータが分類されます。検証セットの結果は、最良のモデルを選択するのに使用されます。この例において、1つの近傍点(K = 1)に基づいたモデルの誤分類率が最も小さくなっています。また、テストセットでも、1つの近傍点(K = 1)に基づいたモデルの誤分類率が最も低いです。
|
7.
|
「BAD」の赤い三角ボタンをクリックし、[予測式を発行]を選択します。
|
|
8.
|
[近傍点の個数, K]の隣は、デフォルト値の1のままにします。
|
|
9.
|
[OK]をクリックします。
|
予測式は、「計算式デポ」に保存できます。別のモデルも「計算式デポ」に保存すれば、K = 1近傍モデルと比較できます。『予測モデルおよび発展的なモデル』の「計算式デポ」章を参照してください。