「Process Measurements.jmp」サンプルデータには、ある製品の製造に必要な7種類の工程における測定値が含まれています。各工程の仕様限界は、データテーブルの各列に、列プロパティとして保存されています。まず、工程データの分析を検討してみると、 正規分布でないことがわかります。そのため、「工程能力」プラットフォームで非正規分布に基づく工程能力指数を計算する機能を使用します。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Process Measurements.jmp」を開きます。
|
|
2.
|
[分析]>[一変量の分布]を選択します。
|
|
3.
|
「列の選択」リストから7列すべてを選択し、[Y, 列]をクリックします。
|
|
4.
|
[ヒストグラムのみ]チェックボックスをオンにします。
|
|
5.
|
[OK]をクリックします。
|
|
1.
|
[分析]>[品質と工程]>[工程能力]を選択します。
|
|
2.
|
「列の選択」リストから7列すべてを選択し、[Y, 工程変数]をクリックします。
|
|
3.
|
[Y, 工程変数]リストから7列すべてを選択します。
|
|
4.
|
|
5.
|
[工程分布の設定]をクリックします。
|
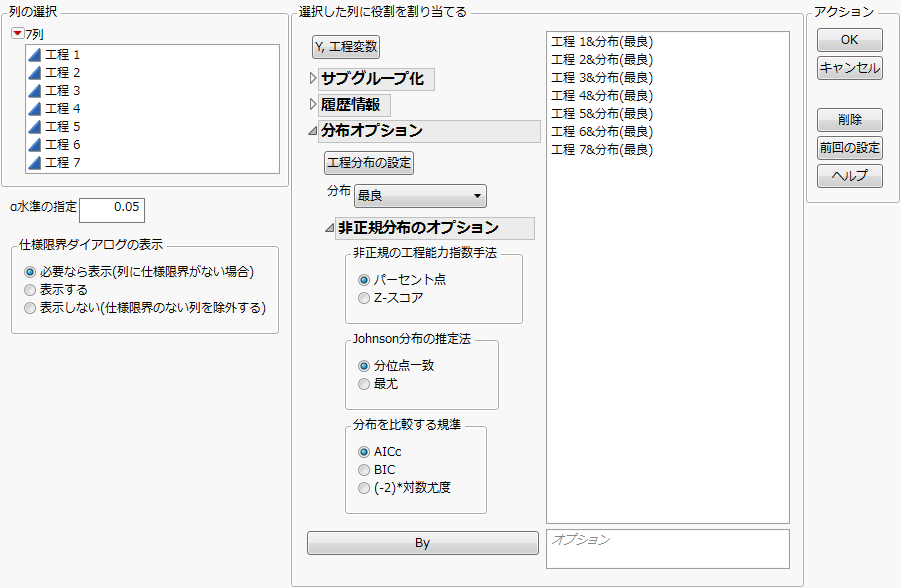
「Y, 工程変数」リストの変数名に「&分布(最良)」という接尾辞が追加されます。[最良]オプションは、各変数に最もあてはまりの良いパラメトリックな確率分布をあてはめます。用意されているパラメトリックな確率分布は、正規分布・ベータ分布・指数分布・ガンマ分布・Johnson分布・対数正規分布・二重正規混合分布・三重正規混合分布・Weibull分布です。設定後の起動ウィンドウを参照してください。
|
6.
|
「非正規分布のオプション」アウトラインを開きます。「非正規の工程能力指数手法」が[パーセント点]、「Johnson分布の推定法」が[分位点一致]、「分布を比較する規準」が[AICc]に設定されていることを確認します。
|
図11.3 設定後の起動ウィンドウ
|
7.
|
[OK]をクリックします。
|
|
8.
|
「ゴールプロット」の赤い三角ボタンメニューから[全体シグマの点にラベル]を選択します。
|
|
9.
|
「工程能力指数プロット」の赤い三角ボタンメニューから[全体シグマの点にラベル]を選択します。
|
図11.4 変数にラベルを表示した初期レポート
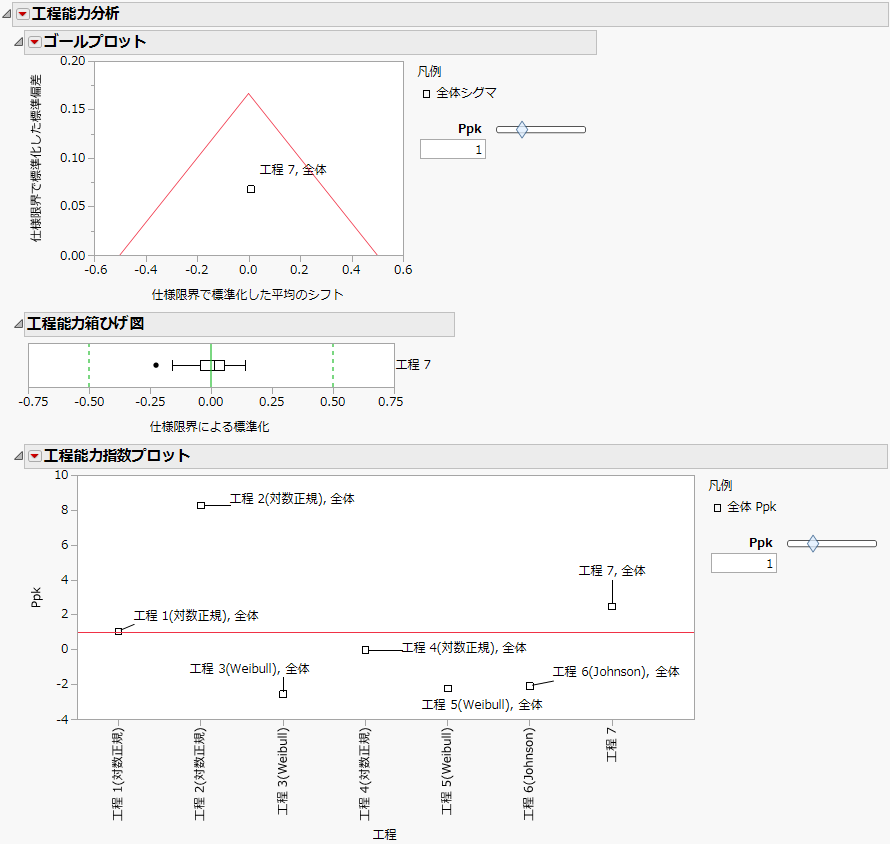
「ゴールプロット」には、「工程 7」の点だけが表示されています。また、「工程能力箱ひげ図」には、「工程 7」の箱ひげ図が1つ表示されています。これは、「工程 7」の最良のあてはめが正規分布であるためです。
「工程能力指数プロット」には、7つの工程すべてのPpk値が表示されます。「工程 2」と「工程 7」の工程能力指数だけが2を上回っています。「工程能力指数プロット」では、変数名のすぐ右側に、最もあてはまりの良い非正規分布の名前が括弧で囲んで表示されます。「工程 7」は、最もあてはまりの良い分布が正規分布であるため、分布名は表示されません。
|
11.
|
「工程能力分析」の赤い三角ボタンのメニューから、[各列に対する詳細レポート]を選択します。
|
|
12.
|
下へスクロールし、「工程能力 工程 4(対数正規)」のレポートを確認してみましょう。
|
図11.5 「工程 4」の詳細レポート
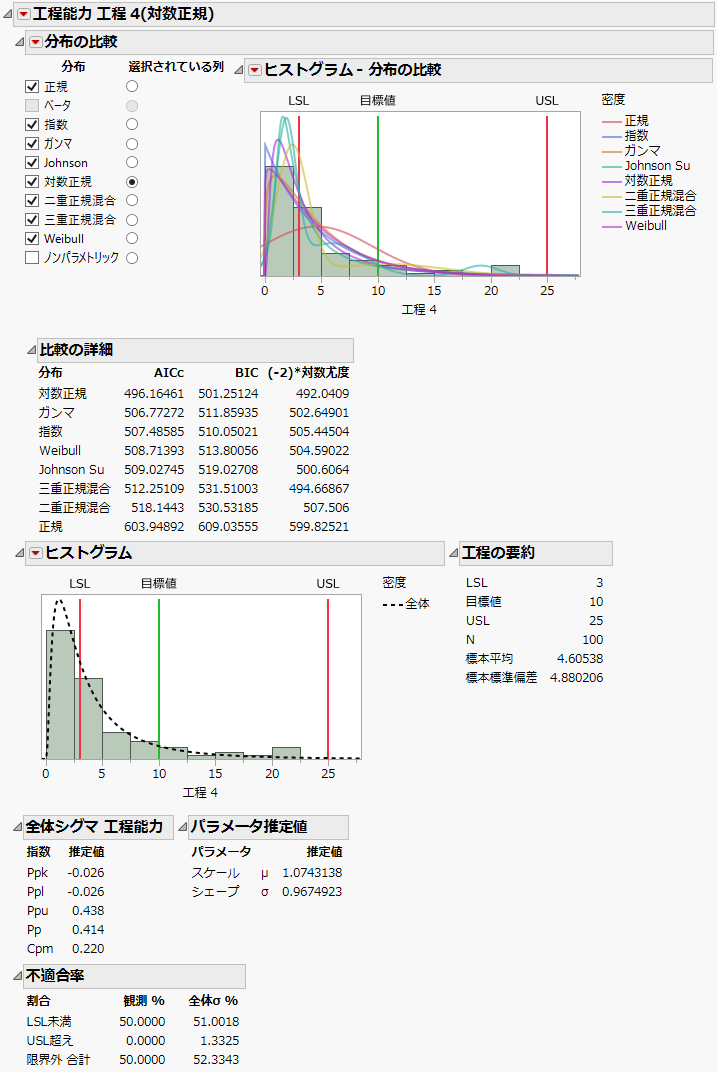
「工程 4」のレポートのタイトルは、工程能力の計算に対数正規分布が使われたことを示しています。「分布の比較」レポートのチェックボックスを見ると、[ノンパラメトリック]と[ベータ]以外のすべてのボックスがオンになっており、8つの分布があてはめられたことがわかります。(これは、起動ウィンドウで[最良]の分布を求めたためです。)「選択されている列」で[対数正規]のラジオボタンがオンになっているのは、「工程 4」のレポートでは対数正規分布を使って工程能力や不適合率の推定値が計算されていることを意味します。