「モデルのあてはめ」での「応答のスクリーニング」の起動
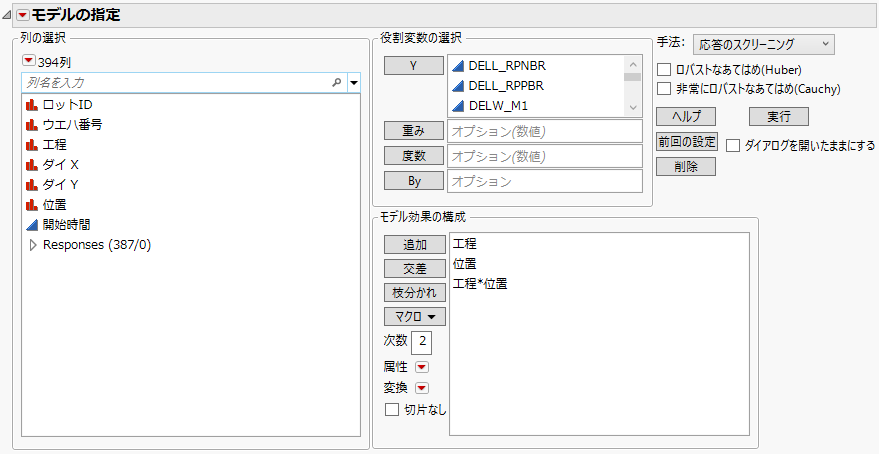
[分析]>[モデルのあてはめ]を選択します。Y変数とモデル効果を指定します。「手法」のリストから[応答のスクリーニング]を選択します。
図21.10 「モデルのあてはめ」ウィンドウの[応答のスクリーニング]
「列の選択」の赤い三角ボタンのメニューにあるオプションの詳細については、『JMPの使用法』の列フィルタメニューを参照してください。
以下の2つのロバスト推定オプションがあります。
ロバストなあてはめ(Huber)
応答変数が連続尺度である場合に、Huberのロバスト法による推定を行います。この推定方法は、外れ値による影響が少ないです。外れ値がない場合、HuberのM推定の結果は、最小2乗推定のものと近くなります。このオプションを選択した場合は、計算時間がかかります。
非常にロバストなあてはめ(Cauchy)
応答変数が連続尺度である場合に、非常にロバストな推定(Cauchy)を行います。この推定方法は、外れ値による影響が少ないです。このオプションでは、誤差がCauchy分布に従うと仮定されます。Cauchy分布は正規分布よりも裾が広く、その結果、外れ値が推定に与える影響が小さくなります。このオプションは、データにある外れ値の割合が大きい場合に有用です。しかし、データが正規分布に近く、外れ値が少ない場合は、このオプションの推定結果は間違ったものになる可能性があります。[Cauchyのあてはめ]オプションは、最尤推定によってパラメータ推定値を算出します。
ヒント: 両方のロバストオプションを選択した場合は、Cauchyの推定だけが実行されます。
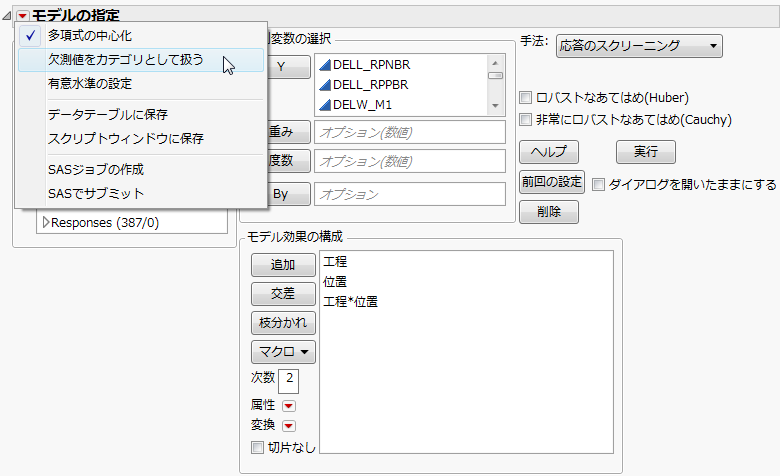
[欠測値をカテゴリとして扱う]オプションを選択すると、欠測値が1つのカテゴリとして扱われます。このオプションを使うと、欠測値がある行も、計算に含まれます。欠測値にも意味がある場合に便利です。このオプションは、「モデルの指定」の赤い三角ボタンのメニューから選択します。
図21.11 [欠測値をカテゴリとして扱う]オプション
「モデルのあてはめ」ウィンドウの詳細については、『基本的な回帰モデル』の「モデルのあてはめ」プラットフォームの起動を参照してください。