启动“响应筛选”平台
通过选择分析 > 筛选 > 响应筛选来启动“响应筛选”平台。
图 21.4 “响应筛选”启动窗口
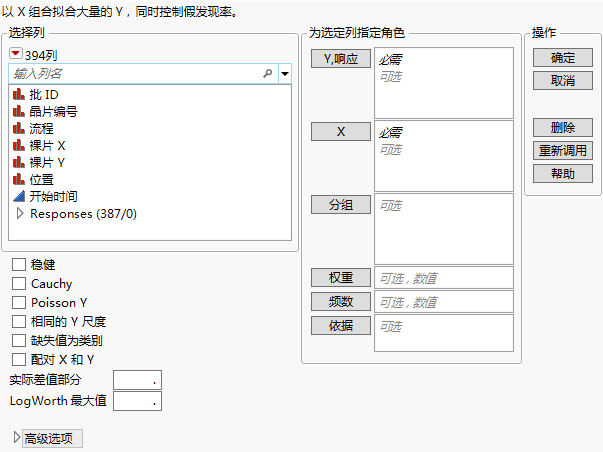
有关“选择列”红色小三角菜单中选项的详细信息,请参见《使用 JMP》中的“列过滤器”菜单。
启动窗口角色
Y,响应
标识包含要分析的测量值的响应列。
X
标识要针对其检验响应的列。
分组
对于指定列的每个水平,分别分析相应的行,但是在单个表和报表中显示结果。
权重
标识其值用于为每行分配权重的列。这些值在分析中作为权重使用。请参见《拟合线性模型》中的权重。
频数
标识其值用于为每个行分配频数的列。这些值允许您将预先汇总数据考虑在内。请参见《拟合线性模型》中的频数。
依据
对于指定列的每个水平,分析相应的 Y 和 X 并在单独的表和报表中显示结果。
启动窗口选项
稳健
对于连续响应,使用稳健 (Huber) 估计来减小离群值的权重。若无离群值,这些估计值接近最小二乘估计值。请注意该选项会增加处理时间。
Cauchy
假定误差服从 Cauchy 分布。Cauchy 分布具有比正态分布更肥大的尾部,从而弱化了对离群值的强调。若您的数据中有较大比例的离群值,该选项会很有用。不过,若您的数据接近正态,只含有少数离群值,该选项会导致不正确的推断。Cauchy 选项使用最大似然和 Cauchy 连结函数估计参数。
Poisson Y
将每个 Y 响应拟合为具有 Poisson 分布的计数。仅为分类 X 执行该检验。当您的响应是计数时,适合使用该选项。
相同的 Y 尺度
当您使用报表的“拟合选定项”选项运行各个分析时,将所有 Y 响应调整为同一尺度。
缺失值为类别
对于任何分类 X 变量,将 X 上的缺失值视为一个类别。
配对 X 和 Y
根据 X 列和 Y 列在 Y,响应和 X 列表中的顺序,仅对与 X 列配对的 Y 列执行检验。第一个 Y 与第一个 X 配对,第二个 Y 与第二个 X 配对等。
实际差值部分
规格范围的比例或估计的六个标准差范围的比例,它表示您认为有实际意义的差值。若“规格限”未设置为列属性,则为响应估计六个标准差的范围。标准差估计值从四分位间距 (IQR) 计算得出,即 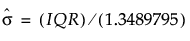 。
。
若未指定“实际差值比例”,则它的值默认为 0.10。实际显著性检验和等价性检验使用该差值确定实际差值。请参见“Compare Means”数据表。
LogWorth 最大值
用于控制涉及 LogWorth 值(p 值的 -log10)的图的尺度。将超过“LogWorth 最大值”的 LogWorth 值标绘为“LogWorth 最大值”以防止 LogWorth 图中出现极端尺度。相关示例,请参见“LogWorth 最大值”选项的示例。
高级选项
包含以下选项:
Kappa
将名为 Kappa 的新列添加到数据表。若 Y 和 X 都是分类变量且具有相同的水平,则提供 kappa。这是 Y 和 X 之间的一致性测度。
相关性
“相关性”选项根据值排序定义的索引计算 Pearson 积矩相关性。
若 X 和 Y 都是二值型,Pearson 积矩计算将给出 Spearman rho 和 Kendall Tau-b。否则,高量值的相关性值指示关联;低量值的相关性值不排除关联。
强制 X 为分类变量
忽略建模类型并将所有 X 列视为分类变量。
强制 X 为连续变量
忽略建模类型并将所有 X 列视为连续变量。
强制 Y 为分类变量
忽略建模类型并将所有 Y 列视为分类变量。
强制 Y 为连续变量
忽略建模类型并将所有 Y 列视为连续变量。
非线程
禁用多线程。