指示预测准确度的 Bagging 示例
Bagging 还用于通过标准误差和其他分布测度指示预测的准确度。在可以在 Bagging 中使用“保存预测公式”选项的平台中,您可以对新观测进行预测并确定它们的准确度。“保存预测公式”选项在“标准最小二乘法”、“广义回归”和“广义线性模型”平台中可用。
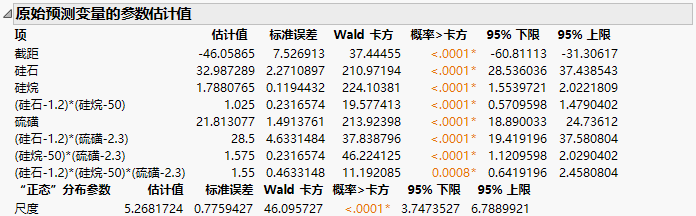
在 Tiretread.jmp 数据表中,假定您只想预测作为三个因子变量的函数的磨损。在该示例中,您拟合一个广义回归模型来预测磨损。接着,您对该模型执行 Bagging。最后,您为新观测生成预测并调查该预测的准确度。这通过获取该预测的置信区间来完成。
拟合广义回归模型
1. 选择帮助 > 样本数据库,然后打开 Tiretread.jmp。
2. 选择分析 > 拟合模型。
3. 选择磨损,然后点击 Y。
4. 从“特质”列表选择广义回归。
5. 选择硅石、硅烷和硫磺,然后点击宏 > 完全析因。
这会将所有项(包括交互作用)添加到该模型。
6. 点击运行。
7. 点击执行。
“广义回归”报表中的参数估计值
执行 Bagging
1. 点击“使用 AICc 验证的正态 Lasso”旁边的红色小三角并选择刻画器 > 刻画器。
“预测刻画器”显示在报表底部。
2. 点击“预测刻画器”红色小三角并选择保存 Bagged 预测。
3. 在“Bootstrap 样本数”旁边输入 500。
4. (可选)在“随机种子”旁边输入 4321。
注意:由于放回抽样是随机的,所以结果会有所不同。要重现本例的精确结果,请设置“随机种子”。
5. 确认选择了保存预测公式。
6. 点击确定。
注意:运行它所需的时间可能比Bagging 改进预测的示例长。更大的样本数可以给出预测分布的更好估计。
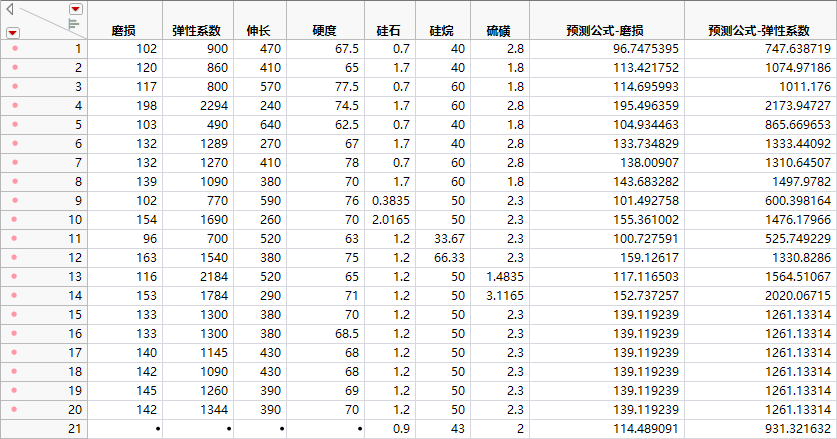
返回数据表。对于每个响应变量,有三个分别表示为预测公式-<列名> Bagged 均值、标准误差-<列名> Bagged 均值、<列名> Bagged 标准差的新列。预测公式-磨损 Bagged 均值列是最终预测。
新观测的预测
您现在有数据表中每个观测的磨损预测以及这些预测的标准误差。假定您有一个观测,对应硅石、硅烷和硫磺的新值分别为 0.9、43 和 2。您可以预测磨损响应并获得该预测的置信区间,因为“保存预测公式”选项保存每个 Bagged 模型的回归方程。因此,使用新因子值生成 M 个预测,以创建可能的预测分布。该均值是最终预测,但是分析分布可以告诉您预测的准确度。
1. 在数据表中,选择行 > 添加行。
2. 在要添加的行数框中输入 1,然后点击确定。
3. 在硅石列下,在新行对应的框中键入 0.9。
4. 在硅烷列下,在新行对应的框中键入 43。
5. 在硫磺列下,在新行对应的框中键入 2。
自动计算新行的所有预测列。
新行的值
6. 选择表 > 转置。
7. 选择“磨损”Bags (500/0) 并点击转置列。
8. 点击确定。
9. 选择分析 > 分布。
10. 选择第 21 行 并点击 Y,列。
注意:第 21 行对应新观测的预测。
11. 点击确定。
12. 点击“第 21 行”旁边的红色小三角并选择显示选项 > 水平布局。
“分布”报表

“分布”报表 中的“分布”报表包含有关每个 Bagged 模型的磨损预测值的分布信息。新观测的磨损最终预测值是 112.3,它是所有 M 个 Bagged 预测的均值。该预测的标准误差为 6.39。您还使用分位数创建新预测的置信区间。例如,新预测的 95% 置信区间为 100.85 到 127.93。