 启动“函数数据分析器”平台
启动“函数数据分析器”平台
通过选择分析 > 专业建模 > 函数数据分析器来启动“函数数据分析器”平台。
“函数数据分析器”启动窗口
有关“选择列”红色小三角菜单中选项的详细信息,请参见《使用 JMP》中的“列过滤器”菜单。
启动窗口包含对应三种不同数据格式的选项卡。
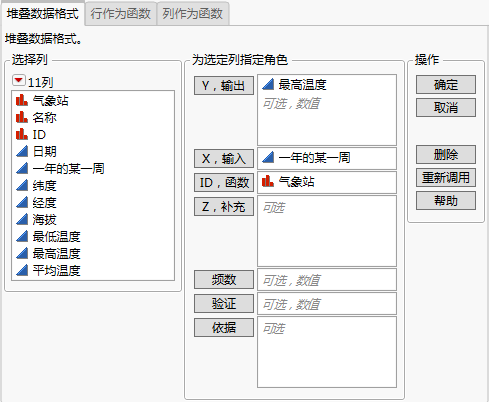
堆叠数据格式
在该数据格式中,每行对应于一个观测。输出、输入和 ID 变量具有单独的列。
注意:堆叠数据格式是唯一允许您指定多个函数过程的数据格式。若您在“堆叠数据格式”选项卡中分配了多个列给 Y,输出,则单独分析每个 Y 变量。“拟合组”报表包含 Y 变量的各个报表。
行作为函数
在该数据格式中,每行对应于 ID 变量的一个水平的完整输出函数。每列是输入变量的一个水平。
警告:“行作为函数”格式假定观测在输入域中的间距相等,除非使用了“FDE X”列属性。“FDE X”列属性支持该数据格式使用列名中指定的输入变量。
列作为函数
在该数据格式中,每列对应于 ID 变量的一个水平的整个输出函数。每行对应于输入变量的一个水平。
 启动窗口选项
启动窗口选项
Y,输出
分配函数过程 f(t)。对于 ID 变量的每个水平,必须有至少两个观测的输出值。
X,输入
(适用于“堆叠数据格式”和“列作为函数”。)分配输入变量 t。若没有为“X,输入”指定变量,则使用行号。使用行号假定观测值在输入域中是等间距的。
ID,函数
(适用于“堆叠数据格式”和“行作为函数”。)将 ID 变量分配给每个函数。若未在“堆叠数据格式”选项卡中分配 ID 变量,则假定所有观测值只来自一个函数。
Z,补充
(适用于“堆叠数据格式”和“行作为函数”。)分配一个或多个补充变量。“函数数据分析器”平台中的任何计算都不使用补充变量,所以包括补充变量不影响结果。补充变量是您可能希望在将来分析“函数数据分析器”的结果时使用的变量。指定补充变量时,它们将包含在由“保存数据”和“保存汇总”选项创建的表的补充列组中。这些列保留在原始数据表中指定的任何列属性。
频数
(仅适用于“堆叠数据格式”。)分配一个列,其数值表示分析中每行的频数。频数列的作用是扩展数据表,以便将具有整数频数 k 的任意行扩展为 k 个相同的行。
验证
分配包含两个非重复值的可选数值列。较小的值定义训练集,较大的值定义验证集。若有两个以上的值,则最小的值定义训练集,所有其他值定义验证集。
注意:“验证”选项允许您提供完整函数而非每个函数的观测样本。因此,具有相同 ID 值的所有观测必须分类为测试或验证。在这两个集中不能有具有相同 ID 值的观测。有关此类验证列的详细信息,请参见分组验证列。
若在“选择列”列表中没有选择任何列的情况下点击“验证”按钮,您可以向数据表添加一个验证列。有关“生成验证列”实用工具的详细信息,请参见生成验证列。
依据
分配用于创建报表的一个列,该报表包括变量的每个水平的单独分析。若指定了多个“依据”变量,将为“依据”变量水平的每种可能组合生成单独的分析。