针对“多个表,交叉引用”的启动窗口
通过选择分析 > 消费者研究 > MaxDiff 启动 MaxDiff 平台。从“数据格式”菜单中为多个表选择多个表,交叉引用。
针对“多个表,交叉引用”数据格式的启动窗口
有关“选择列”红色小三角菜单中的选项的详细信息,请参见《使用 JMP》中的“列过滤器”菜单。
若采用“多个表,交叉引用”,则启动窗口包含三个部分:
• 特征数据
• 响应数据
• 对象数据
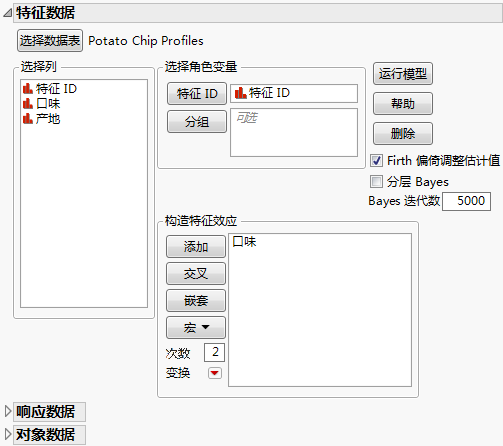
特征数据
特征数据表描述的是与每个选择关联的特性。每个选择可以包含很多不同的特性,每个特性通过数据表中的一列来显示。每个可能的选择都对应一行,而且它们都有唯一的 ID。
选择数据表
选择或打开包含特征数据的数据表。选择“其他”可打开当前尚未打开的文件。
特征 ID
每行选择组合的标识符。若特征 ID 列不能唯一标识特征数据表中的每行,您需要添加分组列。添加分组列,直到分组和特征 ID 列的组合能够唯一标识该行或特征。
分组
一列,在该列与“选择集 ID”列一同使用时,可唯一指定每个选择集。例如,若对于调查 = A 特征 ID = 1,对于调查 = B 另有一个特征 ID = 1,则调查将用作分组列。
构造特征效应
添加从特征中的特性构造的效应。
有关“构造特征效应”面板的信息,请参见《拟合线性模型》中的构造模型效应。
Firth 偏倚调整估计值
计算修正偏倚的 MLE,以便生成比没有修正偏倚的 MLE 更准确的估计值和检验。这些估计值还可缓解 Logistic 模型中常见的分离问题。有关 Logistic 回归中的分离问题的讨论,请参见 Heinze and Schemper (2002)。
 分层 Bayes
分层 Bayes
使用 Bayes 方法估计特定于测试对象的参数。请参见Bayes 参数估计值。
 Bayes 迭代数
Bayes 迭代数
(仅在选定“分层 Bayes”时适用。)用来估计对象效应的自适应 Bayes 算法的迭代总次数。该数字包括废弃的 burn-in 迭代期。burn-in 迭代次数等于启动窗口中指定的“Bayes 迭代数”的一半。
响应数据
“响应数据”分级显示项 显示使用 Potato Chip Responses.jmp 填充的“响应数据”分级显示项。
“响应数据”分级显示项
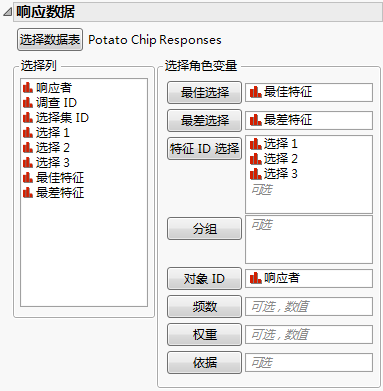
响应数据表包含研究结果。其中提供了每个试验的选择集 ID,以及测试对象选定的最佳和最差特征。响应数据通过选择集列和选择响应列链接到特征数据。当数据中包含多个组时,分组变量可用于对选择指标进行分组匹配。
选择数据表
选择或打开包含响应数据的数据表。选择“其他”可打开当前尚未打开的文件。
最佳选择
“响应”表列,其中包含测试对象指定为“最佳”特征的特征 ID。
最差选择
“响应”表列,其中包含测试对象指定为“最差”特征的特征 ID。
特征 ID 选择
对于每个选择集,包含可能选择集的特征 ID 的列。至少有三个特征。
分组
一列,在该列与已选择的特征 ID 列一同使用时,可唯一指定每个选择集。
对象 ID
用于研究参与者的唯一标识符。
频数
包含频数的列。若 n 是给定行的频数变量的值,则该行在计算中使用 n 次。若它小于 1 或缺失,则 JMP 不使用它来计算任何分析。
权重
包含数据表中每个观测的权重值的列。仅当权重值大于零时才在分析中包含该权重。
依据
为依据变量的每个水平生成单独的报表。若分配了多个依据变量,则为依据变量的每种可能组合都生成一个单独的报表。
对象数据
“对象数据”分级显示项 显示使用 Potato Chip Subjects.jmp 填充的“对象数据”分级显示项。
“对象数据”分级显示项
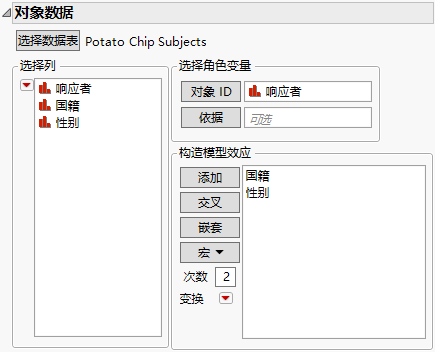
注意:对象数据表是可选的,这取决于是否对对象效应建模。
对象数据表包含“对象 ID”,以及每个测试对象的一个或多个特性或特征列。对象数据表包含与测试对象数相同的行数,还有一个标识符列,该列与响应数据表中的列可以相互匹配。
注意:您可以将对象数据放入响应数据表,但您需要在“对象数据”分级显示项中指定对象效应。
选择数据表
选择或打开包含对象数据的数据表。选择“其他”可打开当前尚未打开的文件。
对象 ID
测试对象的唯一标识符。
依据
为依据变量的每个水平生成单独的报表。若分配了多个依据变量,则为依据变量的每种可能组合都生成一个单独的报表。
构造模型效应
添加由对象数据表中的列构造的效应。
有关“构造模型效应”面板的信息,请参见《拟合线性模型》中的构造模型效应。