功效分析
“功效分析”分级显示项为您模型中的参数计算检验功效。功效是检测到给定大小的活跃效应的概率。“功效分析”分级显示项帮助您评估您的设计检测具有实际意义的效应的能力。功效越高,您越可能检测到显著效应(假设前提是您的系数和 RMSE 假设均正确)。功效取决于试验次数、显著性水平和估计的误差变异。特别是您可以决定是否需要增加额外的试验。
本节涉及以下主题:
• 功效分析概述
• 功效分析详细信息
功效分析概述
为“模型”分级显示项中列出的效应计算功效。它们包括连续因子、离散数值因子、分类因子、分区组因子、协变量因子和混料因子。这些检验针对各个模型参数和整体效应。有关如何计算功效的详细信息,请参见功效计算。
功效是在模型参数的指定值下拒绝“无效应”原假设的概率。实际上,您关注的不是模型参数的值,而是检测响应均值中具有实际意义的差值。在“功效分析”分级显示项中,您可以针对预期系数的指定值计算预期响应。这帮助您确定与要检测的响应均值差值相关的系数值。
Coffee Data.jmp 的功效分析 显示 Design Experiment 文件夹下 Coffee Data.jmp 样本数据表中设计的“功效分析”分级显示项。“模型”脚本中指定的模型是仅包含主效应的模型。
Coffee Data.jmp 的功效分析
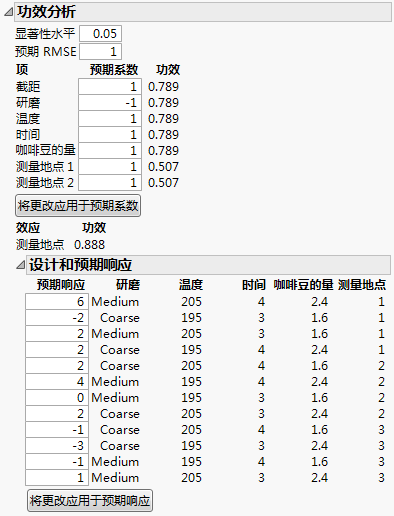
在“功效分析”分级显示项中,您可以:
• 指定反映要检测的差值的系数值。您在分级显示项的上面部分将这些值作为预期系数输入。
• 指定预期响应值并应用它们来确定相应的预期系数。您在“设计和预期响应”面板中指定预期响应。
功效分析详细信息
指定“显著性水平”和“预期 RMSE”的值。它们用于计算针对模型参数检验的功效。
显著性水平
在“无效应”假设为真时拒绝该假设的概率。功效计算在您输入值后立即更新。
预期 RMSE
误差变异的平方根的估计值。功效计算在您输入值后立即更新。
“功效分析”报表的上面部分打开时显示预期系数的默认值(Coffee Data.jmp 的功效分析)。默认值基于 Delta。请参见高级选项 > 设置功效的 Delta。
注意:若设计超饱和(这意味着要评估的参数个数超过试验次数),则预期系数设置为 0。
为 Coffee Data.jmp 指定的可能的预期系数值 显示“功效分析”报表的上面部分,其中已指定了预期系数的值。这些值反映您要检测的差值。
为 Coffee Data.jmp 指定的可能的预期系数值

针对各个参数的检验
“项”列包含模型项的列表。对于每个项,“预期系数”列包含该项的值。“功效”列中的值是以下检验的功效:若预期系数给定了系数的真实值,该项的系数为 0。
项
与要检测的系数相关的模型项。
注意:模型项在“功效分析”报表中显示的顺序可能不同于它们在使用标准最小二乘法得到的“参数估计值”报表中的顺序。仅当模型包含的交互作用具有大于 1 的自由度时,该顺序才会不同。
预期系数
与模型项相关的系数的值。该值用于功效的计算。这些值还用于计算“设计和预期响应”分级显示项中的“预期响应”列。当您在“预期系数”列中设置新值时,点击将更改应用于预期系数可更新“功效”和“预期响应”列。
注意:预期系数对于连续效应的默认值为 1。它们对于分类效应具有交替值 1 和 –1。您可以通过从红色小三角菜单中选择高级选项 > 设置功效的 Delta 来指定 Delta 的值。若您更改 Delta 的值,预期系数的值会更新以便它们的绝对值为 Delta 的一半。请参见高级选项 > 设置功效的 Delta。
功效
当指定的预期系数给出真实系数值时拒绝“无效应”原假设的概率。对于与数值因子相关的系数,响应均值的变化量(基于模型)是系数值的两倍。对于与分类因子相关的系数,因子各个水平上响应均值的变化量(基于模型)是预期系数的绝对值的两倍。
计算中使用指定的“显著性水平”和“预期 RMSE”。有关功效计算的详细信息,请参见单个参数的功效。
将更改应用于预期系数
当您在“预期系数”列中设置新值时,点击将更改应用于预期系数可更新“功效”和“预期响应”列。
针对具有两个以上水平的分类效应的检验
若您的模型包含具有两个以上水平的分类效应,则以下列显示在“将更改应用于预期系数”按钮下方:
效应
分类效应。
功效
检验无效应的功效计算。检验的原假设是:与效应对应的所有模型参数为零。要检测的差值由“预期系数”列中的值定义,这些值对应于效应的模型项。功效计算反映由预期系数决定的响应均值的差值。
计算中使用指定的“显著性水平”和“预期 RMSE”。有关功效计算的详细信息,请参见分类效应的功效。
“设计和预期响应”分级显示项
“设计和预期响应”分级显示项在“预期响应”列之后显示设计。第一列中的每个条目是对应于设计设置的“预期响应”。使用“预期系数”计算“预期响应”。
Coffee Data.jmp 的预期响应 显示对应于为 Coffee Data.jmp 指定的可能的预期系数值 中所示的“预期系数”值的“设计和预期响应”分级显示项。
Coffee Data.jmp 的预期响应
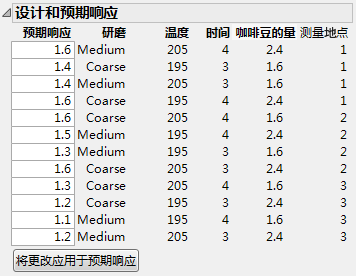
在“预期响应”列中,您可以为因子的每个设置指定值。这些值反映您要检测的差值。
点击将更改应用于预期响应可同时更新“预期系数”和“功效”列。
预期响应
使用“预期系数”值作为模型中的系数获得的响应值。该分级显示项首次显示时,“预期响应”值的计算基于“预期系数”列中的默认值。当您在“预期响应”列中设置新值时,点击将更改应用于预期响应可更新“预期系数”和“功效”列。
设计
“预期响应”列右侧的列显示设计中所有试验的因子设置。
将更改应用于预期响应
当您在“预期响应”列中设置新值时,点击将更改应用于预期响应可更新“预期系数”和“功效”列。
咖啡实验的功效分析
考虑 Coffee Data.jmp 数据表中的设计。假定您关注的是设计检测各个量对浓度影响的功效。回想一下,研磨是两水平的分类因子,温度、时间和咖啡豆的量是连续因子,测量地点是三水平的分类(分区组)因子。
在该示例中,忽略测量地点作为分区组因子的角色。您要关注的是测量地点对浓度的影响。因为测量地点是三水平的分类因子,它在“参数”列表中用两项来表示:测量地点 1 和测量地点 2。
您尤其关注检测浓度均值的以下变化量的概率:
• 您将研磨从“Coarse”变为“Medium”时均值变化了 0.10 个单位。
• 您将温度、时间和咖啡豆的量从低水平变为高水平时均值变化了 0.10 个单位或更多。
• 测量地点 1 和 2 分别导致均值比整体预期均值增加了 0.10 个单位。这对应于测量地点 3 导致均值比整体预期均值减少了 0.20 个单位。
您将 0.05 设置为“显著性水平”。对于固定设计设置,估计的浓度标准差为 0.1,输入它作为“预期 RMSE”。
在“预期系数”面板中输入了用户指定内容的“功效分析”分级显示项 显示输入了这些值后的“功效分析”节点。您明确指定了“显著性水平”、“预期 RMSE”和每个“预期系数”的值。
点击“将更改应用于预期系数”时,“预期响应”值会更新以反映您指定的模型。
在“预期系数”面板中输入了用户指定内容的“功效分析”分级显示项
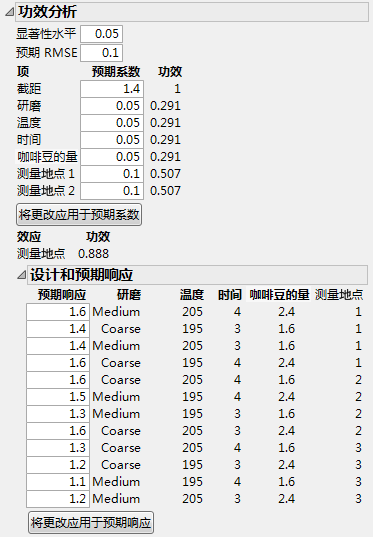
回想一下,温度是具有编码水平 -1 和 1 的连续因子。考虑原假设为温度对浓度没有影响的检验。在“预期系数”面板中输入了用户指定内容的“功效分析”分级显示项 显示该检验在温度的各水平上检测 0.10 (=2*0.05) 个单位差值的功效仅为 0.291。
现在考虑检验整个测量地点效应,其中测量地点是三水平的分类因子。考虑原假设为测量地点对浓度没有影响的检验。这其实是当您运行分析 > 拟合模型时“效应检验”报表中针对分类因子提供的普通 F 检验。请参见《拟合线性模型》中的效应检验。
该检验的功效直接显示在“将更改应用于预期系数”按钮下方。模型项“测量地点 1”和“测量地点 2”的“预期系数”下的条目都为 0.10。这些设置暗示两个测量地点的效应都使浓度高于整体预期均值 0.10 个单位。对于“测量地点 1”和“测量地点 2”系数的这些设置,“测量地点 3”对浓度的影响是使浓度比整体预期均值减少 0.20 个单位。在“预期系数”面板中输入了用户指定内容的“功效分析”分级显示项 显示检验用于检测至少这个量的差值的功效为 0.888。