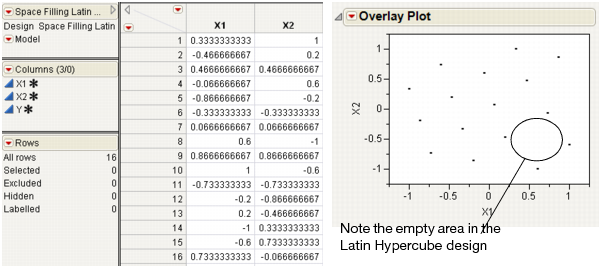
However, as the example at the top in Two-factor Latin Hypercube Design shows, the Latin Hypercube design does not necessarily do a great job of space filling. This is a two-factor Latin Hypercube with 16 runs and with the factor level settings set between -1 and 1. Note that this design seams to leave a hole in the bottom right of the overlay plot.
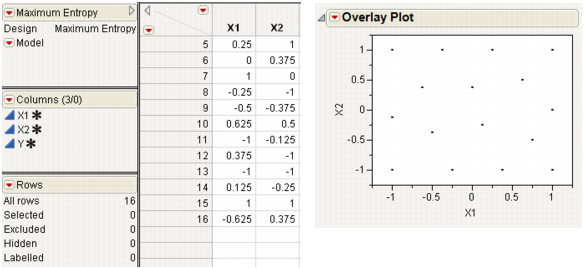
The Maximum Entropy design is a competitor to the Latin Hypercube design for computer experiments because it optimizes a measure of the amount of information contained in an experiment. See the technical note below. With the factor levels set between -1 and 1, the two-factor Maximum Entropy design shown in Two-Factor Maximum Entropy Design covers the region better than the Latin hypercube design in Two-factor Latin Hypercube Design. The space-filling property generally improves as the number of runs increases without bound.
Technical Maximum Entropy designs maximize the Shannon information (Shewry and Wynn (1987)) of an experiment, assuming that the data come from a normal (m, s2 R) distribution, where
is the correlation of response values at two different design points, xi and xj. Computationally, these designs maximize |R|, the determinant of the correlation matrix of the sample. If xi and xj are far apart, then Rij approaches zero. If xi and xj are close together, then Rij is near one.