Report Analyses and Calculations
How does JMP Clinical handle date and time information?
Times and dates are an integral part of the data generated in all clinical trials. At least one timing variable must be included in all SDTM subject-level domain data sets. JMP Clinical can use time and date variables in a variety of numeric formats; for example, the ISO 8601 standard: YYYY-MM-DDhh:mm:ss, shown here:
| • | YYYY is the four-digit year, |
| • | MM is the two-digit month (values rage from 01-12), |
| • | DD is the two-digit day (values range from 01-31), |
| • | hh is the two-digit hour (values range from 00-23) |
| • | mm is the two-digit minutes (values range from 00-59), and |
| • | ss is the two-digit seconds (values range from 00-59). |
Additional, allowable characters include
| • | T, which indicates that time information is included (omitted if no time component is included), |
| • | -, which either separates the date elements or can be used to indicate missing date components |
| • | :, which separates time elements, |
| • | /, which can be used to separate the date components from the time components, and |
| • | P, which serves as a duration indicator and precedes the date/time components representing the duration of an event or intervention. |
Dates and times can be and are expressed as complete dates/times, partial date/times, or incomplete date/times. JMP Clinical recognizes each of these elements and handles partial or incomplete dates/times as described in the separate FAQ: How does JMP Clinical handle partial or incomplete date and time information?
How does JMP Clinical handle partial or incomplete date and time information?
When date/time values are either partial or incomplete, JMP Clinical invokes a “first moment” rule. In these cases, when a date/time component is not included in the ISO 8601 value, that value is assumed to be the first possible value. For example, if the value for an event is listed as “2013-12”, JMP Clinical assumes that the event occurred on the first day of December 2013. and assigns a day value of “01”.The resulting sort order of partial dates using the first-moment rule is the same as that of the ISO 8601 strings themselves.
Narrative findings are reported as follows:
| • | When a partial date identified (xxDTC for LB, EG or VS), an asterisk (*) is appended to the end of the finding name or test code. You should review the findings for the appropriately reported set of observations. |
| • | When the reference date (RFSTDTC) is partial, an asterisk is appended to the AETERM. You should review all reported dates, study days, and contents for correctness. |
| • | When the AE start date (AESTDTC) is partial, an asterisk is appended to the date in the narrative. You should review all contents of the narrative. |
| • | When the AE end date (AEENDTC) is partial, an asterisk is appended to the date in the narrative. You should review the final outcome and narrative header information for correctness. |
| • | When any of the dosing records have partial dates for exstdtc or exendtc, an asterisk is placed in the drug header that explains dose at time of the event, or the pre- or post-dose status. All text related to the drug should be reviewed. |
| • | When the date of completion or discontinuation (DSSTDTC) is partial, an asterisk is appended to the date in the narrative. You should review these dates for correctness. |
| • | When either or both of the start or stop dates (CMSTDTC or CMENDTC) for Concomitant medications are partial, an asterisk is appended to the end of CMTERM or CMDECOD (based on the selected analysis option). You should review the data for this medication for correctness. |
How do I set values for time and other measures above and/or below default limits?
You must expand the range of the slider control used to specify a value. To change the scale of the slider, right-click on the slider and select from the pop-up menu. Change the upper or lower boundaries in the window that appears, to rescale the slider and click .
How does JMP Clinical identify domains included in a study?
Domains are evaluated for SDTM folder and ADaM folder. Domains from SDTM folder are named using the 2-letter code XX, where XX. can be any two letters. For example, the domain containing adverse event data is AE (the data set name).
Domains from ADAM always contain AD as the first two letters of the domain name. ADSL is constant while other letters following the AD identify the specific domain. For example, ADAE is the ADaM domain AE.
Domains are classified as findings if XXTESTCD is present, interventions if XXTRT is present, or events if XXTERM is present. If domain type cannot be identified for a given folder, the domain is ignored.
In addition, Basic Data Structure (BDS) is supported for ADAM. If PARAMCD and either AVAL or AVALC are present, the domain is considered a findings domain. If other variables are present as above and the domain type cannot be identified, it is ignored. This is true even if XXTESTCD is present since it would not be clear whether to transform ADaM variables or use SDTM variables for the domain.
Once domains are selected for each folder, each domain is represented by one data set. If a domain is present in both ADAM and SDTM, the ADAM domain takes precedence.
The one exception to ADaM's precedence occurs when the DM domain from SDTM contains variables not present in ADSL. In this case, DM is merged with ADSL. Variables that are unique to one data set or the other are all included in the merged data set. However, for variables common to both ADSL and DM, the ADSL variable takes precedence and is included in the merged data set, the DM version is discarded. if the study includes SUPPDM, then DM and SUPPDM are merged prior to the merge with ADSL.
Supplemental domains (SUPPxx) can be used by JMP Clinical. However, because these domains lack the standard data needed for analysis, SUPPxx domains are recognized only when the main domains are present. For example, SUPPAE is recognized when AE is present but is ignored when AE is not found. SUPP, where all supplemental data is within one data set, is not supported in the CDISC specification and will not be used.
How does JMP Clinical use data contained across split domains?
When you add a study, JMP Clinical examines the specified SDTM and ADaM folders and identifies the domains using the standard two-letter designations.
Split domains are identified by three- or four-letter designations. The first two letters correspond to parent domain with one or two additional characters. Split domains may either be present in the specified SDTM folder with the other domains or may be grouped within a single subfolder located in the SDTM folder. This subfolder must be named split. JMP Clinical adds the study as normal, maintaining the file structure, but subsequently treats the split domains as a single unit during analysis.
Note: The split domains are ignored if the major domain (identified by the two-letter designation) is present.
What are Keys and how does JMP Clinical Identify Keys?
Keys
The CDISC SDTM Implementation Guide defines the following terms:
A Natural Key is one or more variables whose contents uniquely distinguish every record (row) in the data set. For example, each row of the DM domain should represent a different subject. The natural keys in this instance could be Study Identifier (STUDYID) and Unique Subject Identifier (USUBJID).
A Surrogate Key is an artificially established single-variable identifier that uniquely identifies rows. This could include any of the xxSEQ variables. For example, if the vital signs data set contained 200 records, the VSSEQ variable could be numbered 1 to 200 to uniquely identify the rows.
Alternatively, xxSEQ can be made part of a natural key so that xxSEQ can count from 1 to ni, where ni is the total number of records for a subject. Here the keys would be STUDYID, USUBJID and xxSEQ.
How does JMP Clinical Identify Keys?
JMP Clinical looks for keys using the following sequence:
| 1 | Text Files |
JMP Clinical looks for presence of xx.txt files (for SDTM) or ADxx.txt files (for ADaM) in keys subfolders located in either the SDTM or ADaM folders where the domains are stored. For each domain (DM, CO, SE, SV, the findings domains, the events domains, and the interventions domains) and ADSL, the JMP Clinical chooses either the xx.txt file (where xx is the domain name) or the ADxx.txt file depending on the library used for each domain. Keys are derived from that text file.
For example, a VS.txt file located in the SDTM folder contains the following fiverows:
USUBJID
VSTESTCD
VISITNUM
VSDTC
VSGRPID
The three variables defined in this text file serve as keys for the analysis.
If keys are not defined, JMP Clinical proceeds to step 3.
Note: Keys files need to present during updates to enable users to change keys during snapshots if needed to account for non-uniqueness of rows based on a past set of keys.
| 2 | SORT Metadata |
SAS PROC SORT can be used to derive the keys. See https://community.jmp.com/t5/JMP-Blog/Truly-efficient-clinical-reviews-it-s-all-about-the-keys/ba-p/30245 for details.
If keys are still not defined, JMP Clinical proceeds to step 4.
Note: This option is not available for SAS Transport files.
| 3 | Derive |
Keys are derived based on the suggested variables above.
How does JMP Clinical determine whether an Event Is a Treatment Emergent Adverse Event?
JMP Clinical uses the TreatmentEmergent SAS macro to determine whether records might be:
| • | Treatment emergent. These are data that begin on or after the first dose of any study drug. |
| • | Pre-treatment. These are data that begin prior to the first dose of any study drug. |
| • | On Treatment. Those are events that begin on or after the first dose of any study drug until the last date of dosing plus the offset1 for end of dosing |
| • | Off-treatment follow-up. These are events that begin after the last date of dosing plus the offset for the end of dosing |
This macro can be applied to event domains (including AE and CE), intervention domains (including CM) and findings domains (including VS) and supplemental domains (including SUPPAE).
Algorithm
The macro used to calculate TEAEs incorporates the following:
| • | Dates with partial times are imputed to the earliest time, 00 seconds, 00 minutes, or 00 hours. |
| • | Partial dates impute to earliest day (1st), and earliest month (Jan). Dates that are completely missing are not imputed. Observations recorded in MH are assumed to have occurred prior to initial dosing. |
| • | If either ADSL.TRTEMFL or xx.xxTRTEM are present with a value of either Yes or Y, the event is considered as treatment emergent. |
| • | The start dates for dosing are determined from ADSL.TRTSDTM. If ADSL.TRTSDTM is not present, ADSL.TRTSDT is used. If ADSL.TRTSDT is not present, DM.RFXSTDTC is used. If DM.RFXSTDTC is not present, the earliest date in EX.EXSTDTC is used. If EX.EXSTDTC is not present, DM.RFSTDTC is used. |
| • | The end dates for dosing are determined from ADSL.TRTEDTM. If ADSL.TRTEDTM is not present, ADSL.TRTEDT is used. If ADSL.TRTEDT is not present, DM.RFXENDTC is used. If DM.RFXENDTC is not present, the latest date in EX.EXENDTC is used. If EX.EXENDTC is not present, DM.RFENDTC is used. |
| • | If neither the date of the event, intervention or finding nor the dosing start date has a time component, treatment emergence status is based solely on the date. |
| • | For AE, CM, and CE, if the date listed is on or after the dosing start date, the event is considered treatment emergent. |
| • | All non-treatment emergent events are considered pre-treatment events. |
| • | Note: All events are considered pre-treatment for those subjects not on treatment. |
| • | For conservativeness, AE and CM are considered treatment emergent and on-treatment when equal to dose datetime or when the date is missing. |
| • | For on-treatment events: |
| • | When neither the date of event, nor the intervention of finding nor the dosing end date has a time component, comparisons are based solely on date. |
| • | For those cases in which the start date is known but the end date is missing, comparisons are based solely on the date and the event is considered on-treatment when the date of the event occurs after the start date. |
| • | For those cases in which both the start date and the end date are known, comparisons are based solely on the date and the event is considered on-treatment when the date of the event occurs between the start date and end date (plus the offset). |
| • | For off-treatment follow-up events: |
| • | When neither the date of event, nor the intervention of finding nor the dosing end date has a time component, comparisons are based solely on date. |
| • | For those cases in which both the start date and the end date are known, the event is considered off-treatment follow-up when the date of the event occurs after the end date (plus the offset). |
How does JMP Clinical handle non-unique Findings test names?
When running Findings reports, JMP Clinical looks for and appends the values from either xxPOS or xxSPEC to the test names in xxTESTCD and xxTEST. This enables you to analyze findings data when multiple findings test names are identical across the variables: xxTESTCD, xxPOS, and xxSPEC.
If test name values are still not unique across categories of xxCAT or xxSCAT (if they exist) after appending the prior variables, a numeric index is appended to non-unique tests so that reports can still be run and tests are not inappropriately combined.
How does JMP Clinical handle supplemental domains?
The Merge supplemental domain option is checked by default in reports where the domain data format remains intact and supplemental can be merged into the output data set. Additionally, reports involving adverse events will have merge supplemental checked by default due to common use of SUPPAE to store treatment emergent flags. All other reports that process or summarize data have the Merge supplemental domain option off by default to improve efficiency and processing of the reports.
If you wish to use information available in a supplemental domain in filtering the data set with custom WHERE statements2, then the Merge supplemental domain option should be checked.
How does JMP Clinical Identify Records across Snapshots?
Keys give us insight into the uniqueness of a record or data set row. The CDISC SDTM Implementation Guide defines the following terms:
| • | Natural Keys are one or more variables whose contents uniquely distinguish every record (row) in the data set. For example, each row of the DM domain should represent a different subject. The natural keys in this instance could be Study Identifier (STUDYID) and Unique Subject Identifier (USUBJID). |
| • | A Surrogate Key is an artificially established single-variable identifier that uniquely identifies rows. This could include any of the xxSEQ variables. For example, if the vital signs data set contained 200 records, the VSSEQ variable could be numbered 1 to 200 to uniquely identify the rows. |
Alternatively, xxSEQ can be made part of a natural key so that xxSEQ can count from 1 to ni, where ni is the total number of records for a subject. Here the keys would be STUDYID, USUBJID, and xxSEQ.
So why is this important? Well, in order to examine a record (row) for differences between two snapshots, there needs to be a way to link these two versions of the record together. This is where the keys come in. Otherwise, JMP Clinical has no way to know which records to match together. Further, in order to save or access notes for a particular record, there needs to be a way to file the note away so that it is accessible later when returning to the record. Again, this is where the keys come in.
Providing JMP Clinical with keys to all of the data domains for a study.
If you have ever used PROC CONTENTS, the output header for a data set contains various information about the data set. One of these pieces of information is “SORTED: YES/NO”. If the data set happens to be sorted (in other words, YES), then additional information is provided in the PROC CONTENTS output after the description of the data set variables. For example, PROC CONTENTS is used on the DM domain for Nicardipine, following row in the output: Sortedby STUDYID USUBJID is added to the metadata that is stored in the SAS formatted data set; the variables used for the data set sort is what JMP Clinical uses to define the keys for a study.
So how can these values be saved to the metadata of a data set? Open the data set in SAS and enter one of the following SAS routines at the command line:
PROC SORT data = DM out = out.DM;
by STUDYID USUBJID;
run;
or
data out.DM(sortedby = STUDYID USUBJID);
set DM;
run;
If the study domains lack the SORTEDBY metadata associated with the data sets, JMP Clinical attempts to derive the keys based on suggestions provided in the SDTM Implementation Guide. However, the keys generated might not be the optimal set for a given domain.
So that happens if the supplied keys do not define the records (rows) uniquely? When the study is first added to JMP Clinical, a duplicate report is provided for each affected domain that details the records (rows) that cannot be uniquely determined. These records (rows) are still labeled as New in JMP Clinical. However, any record-level notes that are system- or user-generated would be associated with two or more records. This might be OK if there are few duplicates to contend with, but any duplicates should be reviewed as potential data errors (data that was mistakenly entered twice). When the study data is updated and redundancies remain, JMP Clinical has no way to match these records. In other words, it cannot assess whether any changes were made to the records or not. Again, if there are few duplicates, these records (rows) can be reviewed at multiple snapshots for correctness.
Some Other Important Tips:
| 4 | When you first add a study, examine the duplicate report. Identify the keys for each domain and make sure any duplicates are kept to a minimum (ideally, not present). Otherwise, the reviewing functionality is not as useful as it ultimately could be. For example, if the vital signs (VS) domain was sorted only by STUDYID and USUBJID using the PROC SORT code above, all records for the subject would be considered duplications. This would include multiple tests (such as heart rate, systolic and diastolic blood pressures) or records belonging to different visits. |
| 5 | If you perform (1) and there are numerous duplications for all domains, remove the study from JMP Clinical and re-add once more-appropriately defined keys have been applied to the data sets. It’s important to get this step correct before the study is updated to new snapshots or record-level notes are generated. |
| 6 | Try to choose the smallest number of variables possible to define the keys, and choose variables that are not likely to change values. If a record has a change in one of the variables that make up the keys, there would be no way to match the record to previous versions of the record. However, since all records have Unique Subject Identifier (USUBJID), it is possible to view all notes at the subject level. Refer to the SDTM Implementation Guide for recommendations. |
| 7 | Given (3), do not use terms that rely on medical coding as part of the keys (in other words, AEDECOD based on MedDRA or CMDECOD based on WHODRUG). There are two reasons for this. First, medical coding might not be immediately available. This provides an opportunity for a missing value of AEDECOD to change to a nonmissing coded term later on. Further, sometimes over the course of a study, coded terms might change based on new insights of the clinical team, so, you should use verbatim terms such as AETERM or CMTRT. |
| 8 | The xxSEQ variable or STUDYID, USUBJID, and xxSEQ set might be good keys to use since these values are unlikely to change. However, the xxSEQ variable must be carefully maintained so that the number never changes for a particular record. For example, suppose a CM data set contains two records: |
|
CMSEQ |
CMTRT |
CMSTDTC |
|
1 |
ASPIRIN |
03-20-1974 |
|
2 |
IBUPROFEN |
and is updated through query with a new medication that actually falls between the first two based on date:
|
CMSEQ |
CMTRT |
CMSTDTC |
|
1 |
ASPIRIN |
03-20-1974 |
|
2 |
IBUPROFEN |
|
|
3 |
VITAMIN C |
03-24-1974 |
It is important that any new records are tacked at the end (and to continue the sequence of CMSEQ). Alternatively, if a record is deleted:
|
CMSEQ |
CMTRT |
CMSTDTC |
|
2 |
IBUPROFEN |
|
|
3 |
VITAMIN C |
03-24-1974 |
The sequence number must be kept consistent (in other words, 1 can never be used again). If you tend to define xxSEQ as a straight 1 to N for all records or 1 to ni for each subject without any concern for what the row is, using xxSEQ as a key is not a good choice.
| 9 | Alternatively, a single non-CDISC variable can be included in each domain and added to the SORTEDBY metadata. A good choice might include a record-identifier variable output from any data management system. |
See the SDTM Implementation Guide for more information.
How does JMP Clinical perform Crossover Analysis?
Refer to Crossover Analyses.
How are disposition events used in different JMP Clinical reports?
JMP Clinical reports reports use and count disposition events in specific ways that differ between reports. Standard Safety Reports and DSUR/PSUR Report count subjects in only the last disposition event they experience, whereas DS Distribution (see Events Distribution) counts a subject once in each disposition event they experience. Mortality Time to Event only shows the disposition event only for censored subjects, so if a subject died they are counted under Death and not for any other disposition event.
How does JMP Clinical define various terms for risk-based monitoring?
Subjects 3 are considered RANDOMIZED if there is at least one record from DS where the index ((DS.DSDECOD4), RANDOMIZED) is true.
Depending on the available information, subjects are considered SCREEN FAILURES if:
| • | the value in either DM.ARM or DM.ACTARM is SCREEN FAILURE, or |
| • | the value in DS.EPOCH is SCREENING, the value in DS.DSCAT is DISPOSITION EVENT, and value in DS.DECOD is COMPLETED, or |
| • | the value in DS.DSEPOCH is SCREENING and the value in DS.DSDECOD is COMPLETED, or |
| • | the subject is not randomized. |
To determine whether the subjects have COMPLETED the trial, a The SAS WHERE Expression can be included on the analysis dialog to select the appropriate DS records (this statement should also select the records that indicate whether a subject has alternatively DISCONTINUED or WITHDRAWN). If this The SAS WHERE Expression is supplied and the value in DS.DSDECOD is COMPLETED, the subject is considered to have completed the trial. Otherwise, based on the available variables, the subject is considered to have completed the trial only if
| • | the value in DS.EPOCH is TREATMENT and the value in DS.DSCAT is DISPOSITION EVENT and the value in DS.DSDECOD is COMPLETED, or |
| • | the value in DS.EPOCH is TREATMENT and the value in DS.DSDECOD is COMPLETED, or |
| • | the value in DS.DSCAT is DISPOSITION EVENT and the value in DS.DSDECOD is COMPLETED. |
Subjects are considered to have DISCONTINUED or WITHDRAWN when a The SAS WHERE Expression is supplied and DS.DSDECOD is ^=COMPLETED. Otherwise, based on the available variables the subject is considered to have discontinued the trial if
| • | the value in DS.EPOCH is TREATMENT and the value in DS.DSCAT is DISPOSITION EVENT and the value in DS.DSDECOD is ^= COMPLETED, or |
| • | the value in DS.EPOCH is TREATMENT and the value in DS.DSDECOD is ^= COMPLETED, or |
| • | the value in DS.DSCAT is DISPOSITION EVENT and the value in DS.DSDECOD is ^= COMPLETED. |
Randomized subjects who have neither completed nor discontinued the trial are considered ONGOING.
Depending on the available information, subjects are considered TREATED if
| • | Date/Time of First Study Treatment (DM.RFXSTDTC) is nonmissing, or |
| • | If records are available for the subject in the EX domain, or |
| • | value for DM.ACTARM is neither SCREEN FAILURE, NOT TREATED, nor NOT ASSIGNED, or |
| • | value for DM.ARM is neither SCREEN FAILURE, NOT TREATED, nor NOT ASSIGNED, or |
| • | subject is randomized, as described above. |
An adverse event (AE) is considered serious (an SAE) if the value in AE.AESER is either Y or YES.
An AE is considered fatal if the value in either AE.AEOUT or is either FATAL or DEATH, or if the value in AESDTH is either Y or YES.
A subject is considered to have signed informed consent if there is a value for Date/Time of Informed Consent (DM.RFICDTC).
A subject is considered to have died if
| • | the value in Date/Time of Death (DM.DTHDTC) is nonmissing, or |
| • | the value in DM.DTHFL is either Y or YES, or |
| • | the subject experienced a fatal AE (as defined above), or |
| • | the subject discontinued the trial with and the value in DS.DSDECOD is either DEATH or DIED or DEAD, or |
| • | the CO domain is available and a comment containing DEATH, DIED, or DEAD. |
Subject discontinuations or withdrawals are separated into various reasons for discontinuation:
| • | If the value in DS.DSDECOD is either DEATH, DIED, or DEAD, then the subject is considered to have Discontinued Due to Death, or |
| • | the CO domain is available and a comment containing DEATH, DIED, or DEAD, or |
| • | If the value in DS.DSDECOD is either LOST TO FOLLOW-UP, LOST TO FOLLOWUP, LOST TO FOLLOW UP, or LTFU, then the subject is considered to be Lost to Followup, or |
| • | If the value in DS.DSDECOD is either ADVERSE EVENT or AE, then the subject is considered to have Discontinued Due to Adverse Event, or |
| • | If the value in DS.DSDECOD is either WITHDRAWAL BY SUBJECT, SUBJECT WITHDRAWAL, WITHDREW CONSENT, or SUBJECT WITHDREW CONSENT, then the Patient Withdrew from Study, or |
| • | If none of the conditions listed above apply, the subject is considered to have Discontinued for Other Reasons. |
How does JMP Clinical calculate the False Discovery Rate (FDR)?
With J treatment comparisons of ordered (smallest to largest) p-values p(j), the FDR p-value (Benjamini and Hochberg, 19955) for the jth hypothesis is:
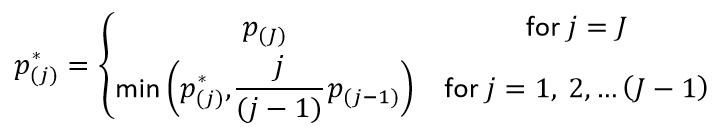
The reference line is drawn at the -log10 transformation of the maximum raw p-value where the corresponding FDR p-value is less than or equal to  .
.
How are risk thresholds defined?
A risk threshold data set is used to 1) define the risk levels for individual variables for RBM analyses 2) specify the contribution of each variable to overall indicators of site risk.
In general, risk thresholds work the same for individual indicators as they do for Overall Indicators and can be defined as described below:
For the ith site or country and the jth risk indicator,
| • | Moderate risk (yellow) occurs when  |
| • | Severe risk (red) occurs when  |
where  is the mean, median or user-supplied center value. The quantity
is the mean, median or user-supplied center value. The quantity  equals
equals  ,
,  , and
, and  , for Direction of Risk Signals equal to B, U, and L, respectively, and
, for Direction of Risk Signals equal to B, U, and L, respectively, and  is the value for the it h site or country and the jth risk indicator.
is the value for the it h site or country and the jth risk indicator.
It is acceptable to specify both yellow and red risk thresholds, one or no risk thresholds. When specifying only a moderate threshold, the Red Percent of Center is left missing in the risk threshold data set so that moderate risk is considered . In instances where values do not meet the criteria for moderate or severe risk, the risk is considered mild (green). Note that for risk thresholds defined using the above criteria, no threshold colors are determined in instances where the mean, median or center value is calculated or set to zero.
. In instances where values do not meet the criteria for moderate or severe risk, the risk is considered mild (green). Note that for risk thresholds defined using the above criteria, no threshold colors are determined in instances where the mean, median or center value is calculated or set to zero.
Risk thresholds can also be defined based solely only the magnitudes of the values observed. In this case,
| • | either moderate risk (yellow) occurs when , or , or |
| • | severe risk (red) occurs when  , , |
where the quantity  is defined as described above.
is defined as described above.
In this case, it is acceptable to specify both thresholds, one threshold, or no risk thresholds at all. When specifying only a moderate threshold, the Red Magnitude is left missing in the risk threshold data set so that moderate risk is  . In cases where neither moderate nor severe risk applies, the risk is considered mild (green).
. In cases where neither moderate nor severe risk applies, the risk is considered mild (green).
There are five overall risk indicators. These are either weighted averages or combinations of the individual risk indicators for which at least one risk threshold is defined, where both the Weight for Overall Risk Indicator and the standard deviation of the indicator > 0.
The first, or Overall Risk Indicator, incorporates all of the variables meeting these criteria into a single measure that signifies the overall risk and performance of a clinical site. This indicator is generated only when the Weight for Overall Risk Indicator exceeds 0 for at least one of the available risk indicators exhibiting variability. If none of the individual indicators have a Weight for Overall Risk Indicator > 0, then the corresponding Overall Risk Indicator is not generated.
Each of the other four overall indicators - Enrollment Metrics, Disposition, Adverse Events, and Manually Entered - combines subsets of the risk indicators based on Category in the risk weight data set. By default, Category matches how variables are grouped in Risk-Based Monitoring, with Manually Entered applied to all user-supplied risk indicators from Update Study Risk Data Set. If no indicators have a Weight for Overall Risk Indicator > 0 for a given category, then the corresponding overall indicator is not provided.
The Weight for Overall Risk Indicator (wj) can either be missing (in this case, it is assumed to be zero) or greater than or equal to zero. The weights are self-normalizing in that each weight is divided by the sum of all weights for variables contributing to the particular overall indicator. The contribution of each indicator to an overall indicator is based on its weight, center value (either mean, median or user-provided center value,  ), standard deviation (
), standard deviation ( ), and direction. In general, the value for an overall indicator for the ith site or country and the jth risk indicator is defined as
), and direction. In general, the value for an overall indicator for the ith site or country and the jth risk indicator is defined as  , where
, where  ,
,  , or
, or  when Direction equals B,U, or L, respectively. This can be interpreted as larger values imply greater risk. By default, all weights are assumed equal to one in the Default Risk Threshold data set, meaning that each variable contributes equally to each overall indicator.
when Direction equals B,U, or L, respectively. This can be interpreted as larger values imply greater risk. By default, all weights are assumed equal to one in the Default Risk Threshold data set, meaning that each variable contributes equally to each overall indicator.