Hinweis: Weitere Informationen zur Plattform „Verteilung“ finden Sie im Kapitel zu Verteilungen in Basic Analysis.
In diesem Beispiel wird die Datentabelle Car Physical Data.jmp verwendet, die Informationen über 116 verschiedene Automodelle enthält.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
Klicken Sie auf OK.
|
|
5.
|
Um das Berichtsfenster zu drehen, klicken Sie auf das rote Dreieck „Weight“ und wählen Anzeigeoptionen > Horizontales Layout aus.
|
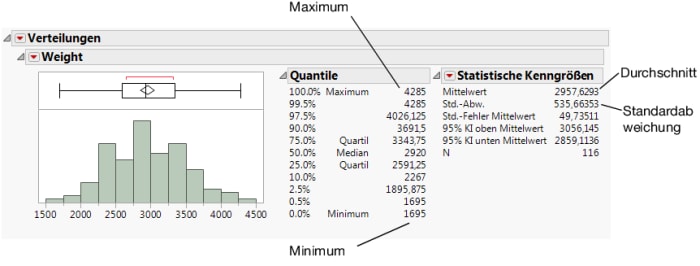
Unter Verwendung der Ergebnisse in Abbildung 7.7 Verteilung des Wertes Weight kann der Planungsexperte die Fragen beantworten.
Das Standard-Berichtsfenster in Abbildung 7.7 Verteilung des Wertes Weight zeigt eine Mindestmenge von Graphen und Statistiken. Zusätzliche Graphen und Statistiken sind im roten Dreiecksmenü verfügbar.
Basierend auf anderen Studienergebnissen hat das Bahnunternehmen festgestellt, dass ein Durchschnittsgewicht von 3000 Pfund das effizienteste Transportgewicht darstellt. Jetzt muss der Planungsexperte herausfinden, ob das durchschnittliche Autogewicht in der allgemeinen Population der untersuchten Autos, die vom Bahnunternehmen transportiert werden können, 3000 Pfund beträgt. Verwenden Sie einen t-Test, um Schlüsse über die zugrunde liegende Grundgesamtheit basierend auf dieser Stichprobe zu ziehen.
|
1.
|
Klicken Sie auf das rote Dreieck „Weight“ und wählen Sie Test Mittelwert aus.
|
|
3.
|
Klicken Sie auf OK.
|
Abbildung 7.8 Testen der Mittelwertergebnisse
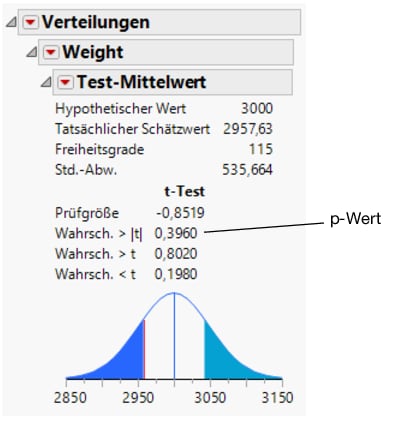
Das primäre Ergebnis eines t-Tests ist der p-Wert. In diesem Beispiel ist der p-Wert 0,396 und der Analyst verwendet ein Signifikanzniveau von 0,05. Da 0,396 größer als 0,05 ist, können Sie daraus nicht den Schluss ziehen, dass das Durchschnittsgewicht von Automodellen in der breiteren Bevölkerung signifikant von 3000 Pfund abweicht. Wäre der p-Wert niedriger gewesen als das Signifikanzniveau, hätte der Experte daraus geschlossen, dass das durchschnittliche Autogewicht in der Grundgesamtheit tatsächlich signifikant von 3000 Pfund abweicht.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
Klicken Sie auf OK.
|
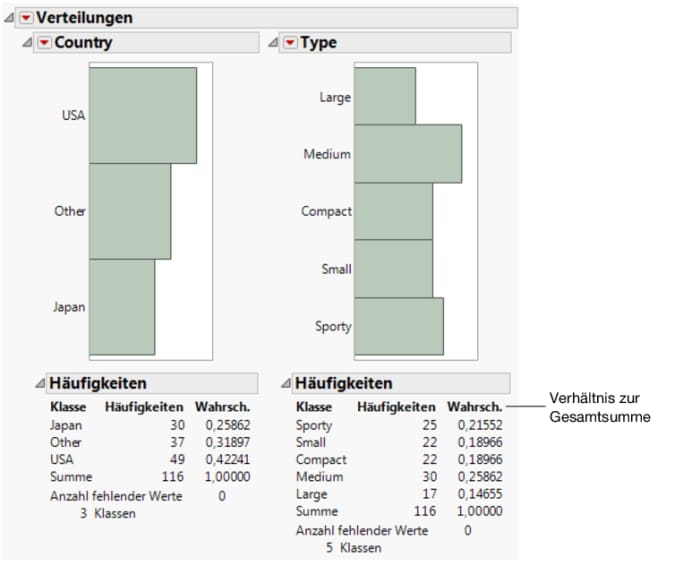
Das Berichtsfenster enthält ein Balkendiagramm und einen Häufigkeitsbericht für Country und Type. Das Balkendiagramm ist eine graphische Darstellung der Häufigkeitsinformationen, die im Häufigkeitsbericht enthalten sind. Der Häufigkeitsbericht enthält Folgendes:
Abbildung 7.10 Japanische Autos
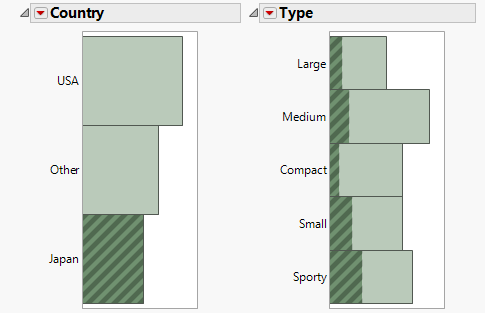
Abbildung 7.11 Andere Autos