Streudiagramme und andere Graphen dieser Art können Ihnen dabei helfen, die Beziehungen zwischen Variablen zu untersuchen. Wenn Sie Beziehungen visualisiert haben, besteht der nächste Schritt darin, die Beziehungen zu analysieren, damit Sie sie numerisch beschreiben können. Diese numerische Beschreibung der Beziehung zwischen Variablen wird als Modell bezeichnet. Besonders wichtig ist, dass ein Modell auch den Durchschnittswert einer Variablen (Y) aus dem Wert einer anderen Variablen (X) prognostiziert. Die X-Variable wird auch als Prädiktor bezeichnet. Im Allgemeinen wird dieses Modell Regressionsmodell genannt.
In JMP erstellen die Plattform Y nach X anpassen und die Plattform Modell anpassen ein Regressionsmodell.
Hinweis: Nur die grundlegenden Plattformen und Optionen werden hier untersucht. Eine Erläuterung aller Plattformoptionen finden Sie in Basic Analysis, Essential Graphing und der unter Über dieses Kapitel aufgeführten Dokumentation.
Tabelle 7.3 Beziehungstypen zeigt die vier primären Typen von Beziehungen.
|
Logistische Regression ist ein weiterführendes Thema. Lesen Sie hierzu das Kapitel zur logistischen Analyse in Basic Analysis.
|
Dieses Beispiel verwendet die Datentabelle Companies.jmp, die Finanzdaten für 32 Unternehmen aus der Pharma- und Computerindustrie enthält.
Zuerst erstellen Sie ein Streudiagramm, um die Beziehung zwischen der Anzahl von Mitarbeitern und dem Umsatz zu ermitteln. Dieses Streudiagramm wurde in Streudiagramm erstellen im Visualisieren Ihrer Daten erstellt. Nachdem ein Ausreißer (ein Unternehmen mit deutlich mehr Mitarbeitern und höheren Umsätzen) ausgeblendet und ausgeschlossen wurde, zeigt das Diagramm in Abbildung 7.12 Streudiagramm von Sales ($M) gegen # Employ das Ergebnis.
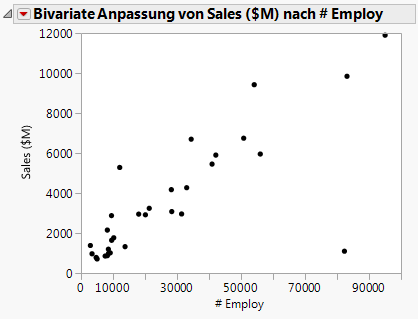
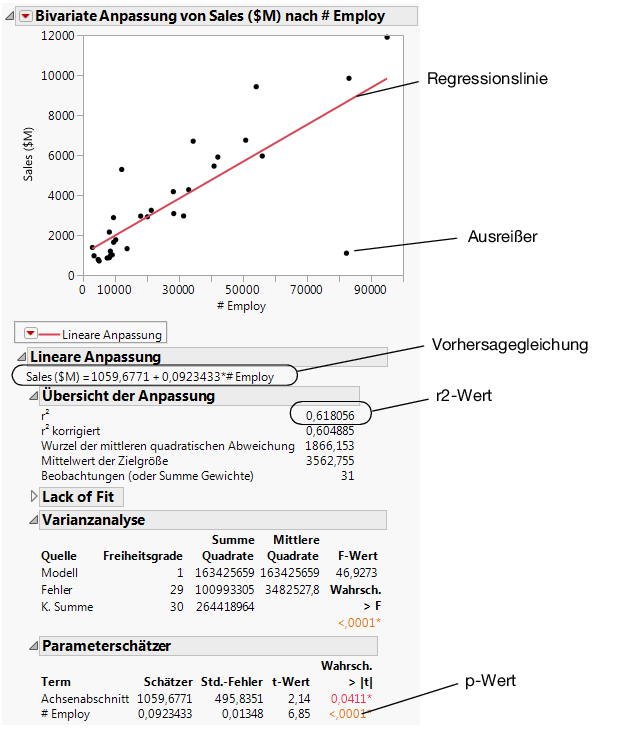
Um den Umsatz aus der Anzahl der Mitarbeiter zu prognostizieren, passen Sie ein Regressionsmodell an. Klicken Sie auf das rote Dreieck für „Bivariate Anpassung“ und wählen Sie Gerade anpassen aus. Eine Regressionslinie wird dem Streudiagramm hinzugefügt und Berichte werden in das Berichtsfenster eingefügt.
Abbildung 7.13 Regressionslinie
|
•
|
p-Wert von < 0,0001
|
|
•
|
Der p-Wert für den Modellterm #Employ ist klein. Dies deutet darauf hin, dass der Koeffizient für #Employ beim Signifikanzniveau 0,05 nicht null ist. Daher lassen sich die Durchschnittsumsätze signifikant besser vorhersagen, wenn die Anzahl der Mitarbeiter in das Vorhersagemodell aufgenommen wird.
|
|
2.
|
|
3.
|
Abbildung 7.14 Vergleichen der Modelle
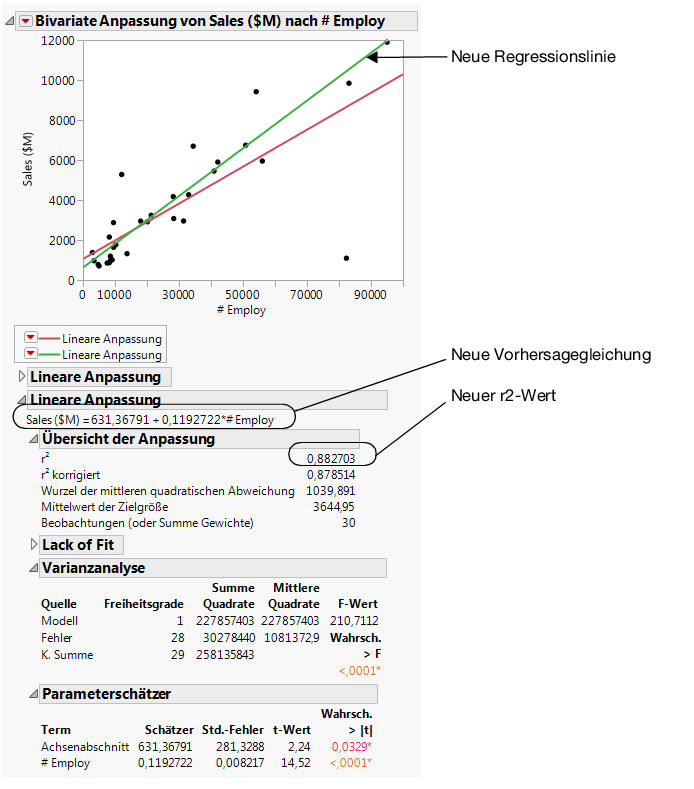
Unter Heranziehung der Ergebnisse in Abbildung 7.14 Vergleichen der Modelle kann der Datenanalyst folgende Schlussfolgerungen ziehen:
Dieses Beispiel verwendet die Datentabelle Companies.jmp, die Finanzdaten für 32 Unternehmen aus der Pharma- und Computerindustrie enthält.
|
1.
|
|
2.
|
Wenn die Beispieldatentabelle Companies.jmp noch offen ist, sind darin vielleicht ausgeschlossene oder ausgeblendete Zeilen. Um die Zeilen in den Standardzustand zurückzusetzen (alle Zeilen eingeschlossen, keine ausgeblendet), wählen Sie Zeilen > Zeileneigenschaften aufheben.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Klicken Sie auf OK.
|
Abbildung 7.15 Gewinne nach Unternehmenstyp
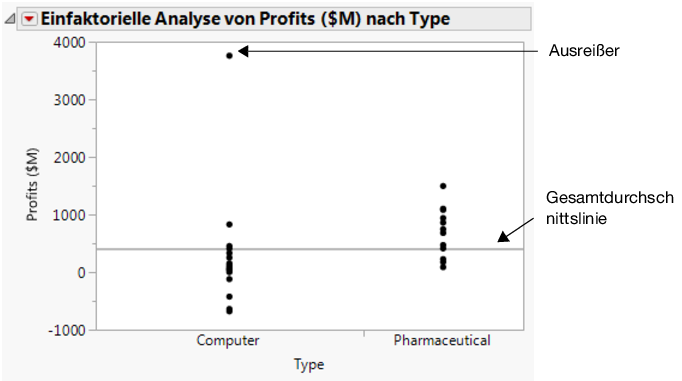
|
2.
|
Wählen Sie Zeilen > Ausschließen/Einschließen. Der Datenpunkt ist in den Berechnungen nicht mehr enthalten.
|
|
3.
|
|
4.
|
Um das Diagramm ohne den Ausreißer neu zu erstellen, klicken Sie auf „Einfaktorielle Analyse von Profits ($M) nach Type“ und wählen Wiederholen > Analyse wiederholen. Sie können das Original-Streudiagramm-Fenster schließen.
|
Abbildung 7.16 Aktualisiertes Diagramm
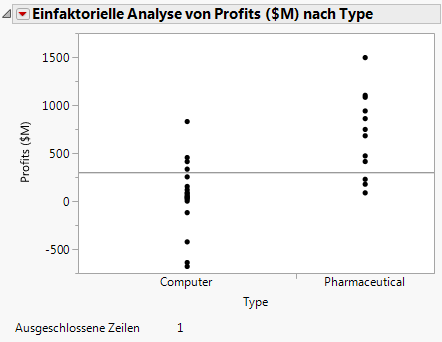
|
–
|
Anzeigeoptionen > Mittelwertlinie. Damit werden dem Streudiagramm Mittelwertlinien hinzugefügt.
|
|
–
|
Mittelwerte und Standardabweichung. Damit wird ein Bericht angezeigt, der Durchschnittswerte und Standardabweichungen enthält.
|
Abbildung 7.17 Mittelwertlinien und Bericht
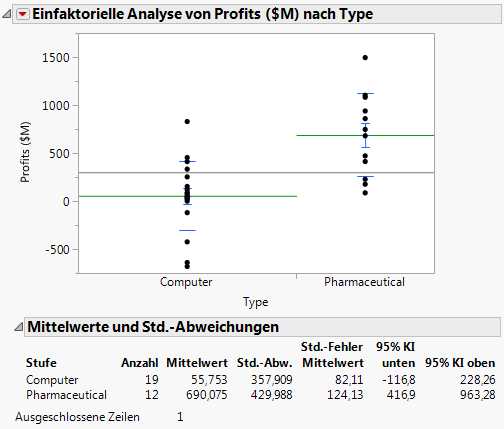
Um diese Fragen zu beantworten, führen Sie einen Zwei-Stichproben-t-Test durch. Bei einem t-Test verwenden Sie Daten aus einer Stichprobe, um Inferenzen über die Grundgesamtheit zu erstellen.
Um den t-Test durchzuführen, klicken Sie auf das rote Dreieck für „Einfaktorielle Analyse“ und wählen Mittelwerte/ANOVA/gepooltes t aus.
Abbildung 7.18 t-Test-Ergebnisse

Der p-Wert 0,0001 ist kleiner als das Signifikanzniveau von 0,05, woraus statistische Signifikanz folgt. Daher kann der Finanzanalyst daraus schließen, dass die Differenz in den Durchschnittsgewinnen für die Stichprobendaten nicht nur zufallsbedingt ist. Dies bedeutet, dass in der Gesamtpopulation die durchschnittlichen Gewinne für Pharmaunternehmen von den durchschnittlichen Gewinnen der Computerunternehmen verschieden sind.
Verwenden Sie die Konfidenzintervallgrenzen, um zu ermitteln, wie groß der Unterschied der Gewinne der beiden Unternehmenstypen ist. Sehen Sie sich die Werte Diff KI oben und DIff KI unten in Abbildung 7.18 t-Test-Ergebnisse an. Der Geschäftsanalyst kommt zu der Schlussfolgerung, dass der durchschnittliche Gewinn von Pharmaunternehmen zwischen 343 Mio. Dollar und 926 Mio. Dollar höher ist als der durchschnittliche Gewinn von Computerunternehmen.
Wenn Sie kategoriale X- und Y- Variable haben, können Sie die Verhältnisse der Ebenen innerhalb der Y-Variablen mit den Ebenen innerhalb der X-Variablen vergleichen.
In diesem Beispiel wird weiterhin die Datentabelle Companies.jmp verwendet. In Durchschnittswerte für eine Variable vergleichen hat ein Finanzanalyst ermittelt, dass Pharmaunternehmen durchschnittlich höhere Gewinne haben als Computerfirmen.
|
1.
|
|
2.
|
Wenn die Datendatei Companies.jmp aus dem vorherigen Beispiel noch offen ist, werden vielleicht Zeilen angezeigt, die ausgeschlossen oder verborgen sind. Um die Zeilen in den Standardzustand zurückzusetzen (alle Zeilen eingeschlossen, keine ausgeblendet), wählen Sie Zeilen > Zeileneigenschaften aufheben.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Klicken Sie auf OK.
|
Abbildung 7.19 Unternehmensgröße nach Unternehmenstyp
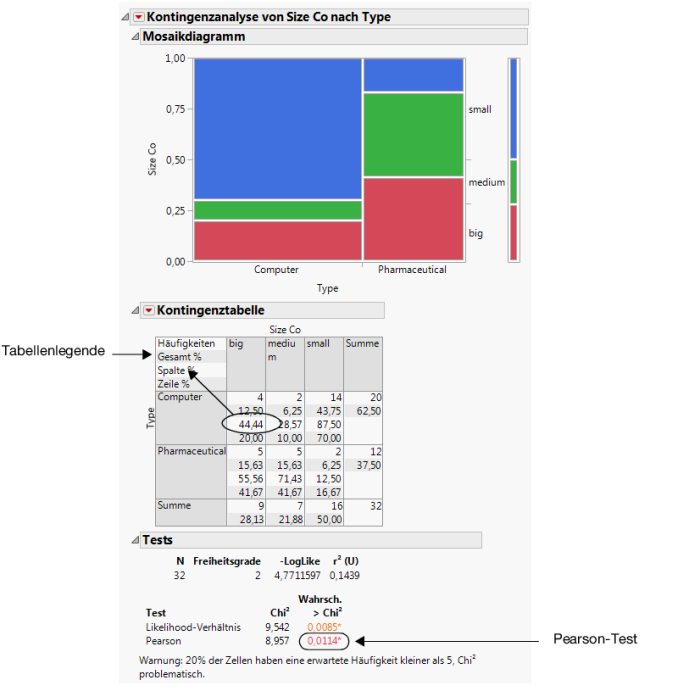
Die Kontingenztabelle enthält Informationen, die auf dieses Beispiel nicht anwendbar sind. Klicken Sie auf das rote Dreieck für „Kontingenztabelle“ und wählen Sie Gesamt % und Spalte % ab, um diese Informationen zu entfernen. Abbildung 7.20 Aktualisierte Kontingenztabelle zeigt die aktualisierte Tabelle.
Abbildung 7.20 Aktualisierte Kontingenztabelle
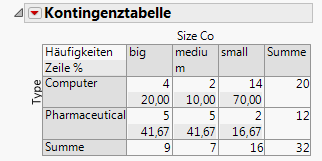
Um diese Frage zu beantworten, verwenden Sie den p-Wert aus dem Pearson-Test im Bericht Tests (Unternehmensgröße nach Unternehmenstyp). Da der p-Wert von 0,011 geringer als das Signifikanzniveau von 0,05 ist, schließt der Geschäftsanalyst daraus:
Im Abschnitt Durchschnittswerte für eine Variable vergleichen wurden Durchschnittswerte über mehrere Ebenen einer kategorialen Variablen verglichen. Um Durchschnittswerte über die Ebenen von zwei oder mehr Variablen auf einmal zu vergleichen, verwenden Sie die Varianzanalyse (oder ANOVA).
|
•
|
Typ (Pharma oder Computer)
|
|
•
|
Größe (klein, mittel, groß)
|
|
1.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
Abbildung 7.21 Graph der Unternehmensprofile
|
6.
|
Wählen Sie den Ausreißer aus, klicken Sie mit der rechten Maustaste darauf und wählen Sie Zeilen > Zeile ausschließen. Der Punkt wird entfernt und die Skala des Graphen wird automatisch aktualisiert.
|
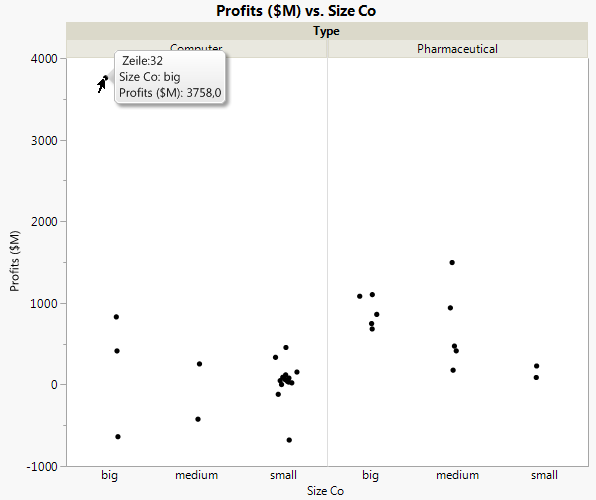
Abbildung 7.22 Graph mit entferntem Ausreißer
|
1.
|
Kehren Sie zur Stichproben-Datentabelle Companies.jmp zurück, in der der Datenpunkt ausgeschlossen ist. Siehe Die Beziehung erkennen.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
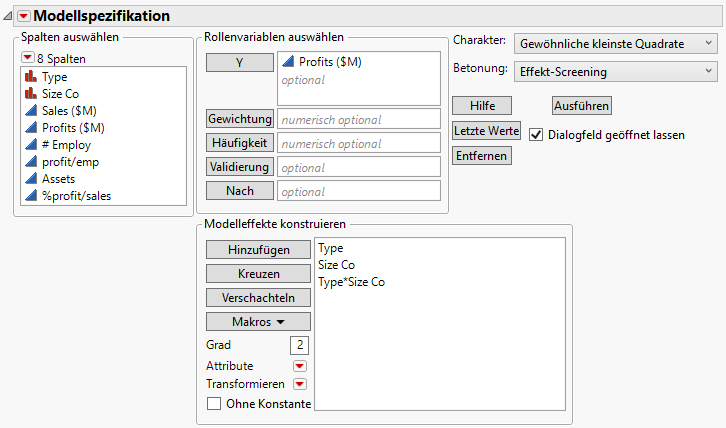
Aus dem Menü „Betonung“ wählen Sie Effektfilterung.
|
|
7.
|
Wählen Sie die Option Dialogfeld geöffnet lassen.
|
Abbildung 7.23 Fenster „Modell anpassen“
|
8.
|
Klicken Sie auf Ausführen. Im Berichtsfenster werden die Modellergebnisse angezeigt.
|
Hinweis: Weitere Informationen zu allen Ergebnissen der Modellanpassung finden Sie im Kapitel zur Modellspezifikation in Fitting Linear Models.
Der Bericht „Effekttests“ (Abbildung 7.24 Bericht „Effekttests“) zeigt die Ergebnisse der statistischen Tests. Es gibt einen Test für jeden Effekt, der im Modell des Fensters „Modell anpassen“ enthalten ist: Type, Size Co und Type*Size Co.
Abbildung 7.24 Bericht „Effekttests“
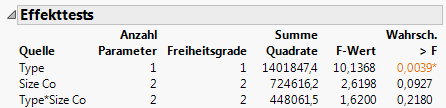
Sehen Sie sich erst den Test für die Wechselwirkung im Modell an: Type*Size Co-Effekt. Abbildung 7.22 Graph mit entferntem Ausreißer zeigte, dass die Pharmaunternehmen offenbar je nach Unternehmensgröße unterschiedliche Gewinngrößen aufweisen. Der Effekttest zeigt aber, dass es keine Wechselwirkung zwischen „type“ und „size“ in Bezug auf den Gewinn gibt. Der p-Wert von 0,218 ist groß (größer als das Signifikanzniveau von 0,05). Daher entfernen Sie diesen Effekt aus dem Modell und führen Sie das Modell erneut aus.
|
2.
|
|
3.
|
Klicken Sie auf Ausführen.
|
Abbildung 7.25 Aktualisierter Bericht „Effekttests“

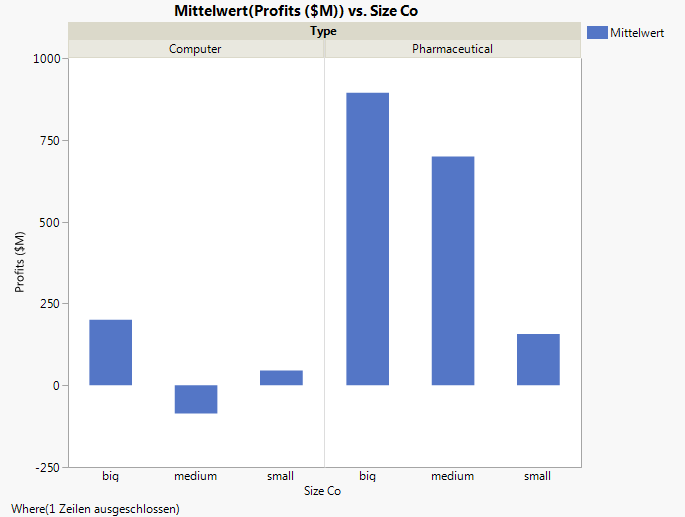
Der p-Wert für den Size Co-Effekt ist groß und weist darauf hin, dass es in der Grundgesamtheit keine Unterschiede basierend auf der Größe gibt. Der p-Wert für den Type-Effekt ist klein und weist darauf hin, dass die Unterschiede, die Sie in den Daten zwischen den Computer- und Pharmafirmen gesehen haben, nicht auf Zufall beruhen.
Im Abschnitt Regression mit einem Prädiktor verwenden wurde gezeigt, wie einfache Regressionsmodelle mit einer Prädiktorvariablen und einer Zielgrößenvariablen erstellt werden. Multiple Regression prognostiziert die durchschnittliche Zielgrößenvariable mit zwei oder mehr Prädiktorvariablen.
In diesem Beispiel wird die Beispieldatentabelle Candy Bars.jmp verwendet, die Ernährungsdaten für Schokoriegel enthält.
|
•
|
Verwenden Sie die multiple Regression, um die durchschnittliche Zielgrößenvariable mit diesen drei Prädiktorvariablen zu prognostizieren.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
Klicken Sie auf OK.
|
Abbildung 7.26 Ergebnisse der Streudiagramm-Matrix
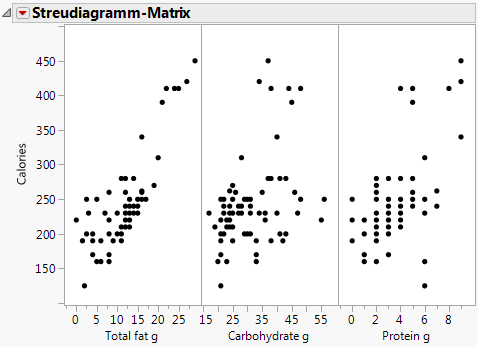
Verwenden Sie weiterhin die Beispieldatentabelle Candy Bars.jmp.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
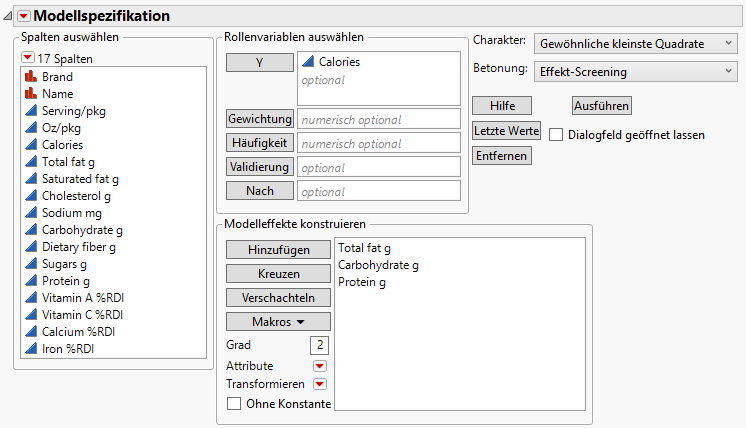
Bei „Betonung“ wählen Sie Effektfilterung.
|
Abbildung 7.27 Fenster „Modell anpassen“
|
5.
|
Klicken Sie auf Ausführen.
|
Hinweis: Weitere Informationen zu allen Modellergebnissen finden Sie im Kapitel zur Modellspezifikation in Fitting Linear Models.
Das „Beobachtete Werte über Vorhersage“-Diagramm zeigt die tatsächlichen Kalorien gegenüber den prognostizierten Kalorien. Wenn sich die prognostizierten Werte den tatsächlichen Werten nähern, rücken die Punkte auf dem Streudiagramm näher zur roten Linie (Abbildung 7.28 Diagramm „Beobachtete Werte über Vorhersage“). Da die Punkte alle sehr nahe an der Linie liegen, können Sie sehen, dass das Modell auf Basis der gewählten Faktoren Kalorien gut prognostiziert.
Abbildung 7.28 Diagramm „Beobachtete Werte über Vorhersage“
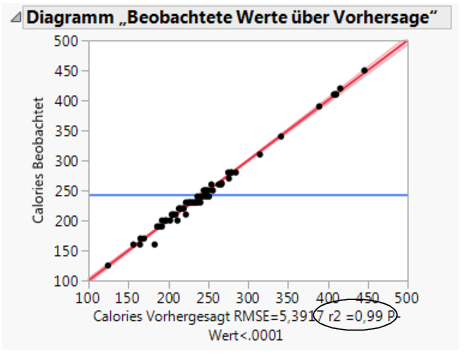
Eine andere Messung der Modellgenauigkeit ist der r2-Wert (der unter dem Diagramm in Abbildung 7.28 Diagramm „Beobachtete Werte über Vorhersage“ erscheint). Der r2-Wert misst den Prozentsatz der Variabilität der Kalorien, der durch das Modell erklärt wird. Ein Wert näher an 1 bedeutet, dass das Modell eine gute Prognose liefert. In diesem Beispiel ist der r2-Wert 0,99.
|
•
|
p-Werte für jeden Parameter
|
Abbildung 7.29 Bericht „Parameterschätzer“
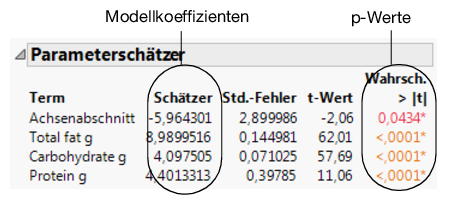
In diesem Beispiel sind die p-Werte alle sehr klein (<0,0001). Dies zeigt, dass alle drei Effekte (Fett, Kohlehydrate und Protein) signifikant zur Prognose der Kalorien beitragen.
Verwenden Sie die Vorhersageanalyse, um zu sehen, wie sich Änderungen der Faktoren auf die prognostizierten Werte auswirken. Die Profillinien zeigen die Größe der Änderungen in Kalorien bei Faktoränderungen. Die Linie für Total fat g ist die steilste. Das bedeutet, dass Änderungen am Gesamtfett die größte Auswirkung auf Kalorien haben.
Abbildung 7.30 Analysediagramm - Vorhersageanalyse
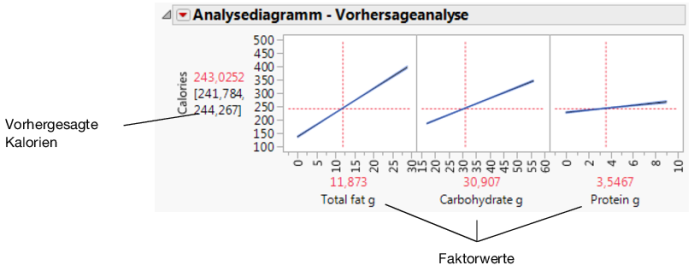
Abbildung 7.31 Faktorwerte für Milky Way
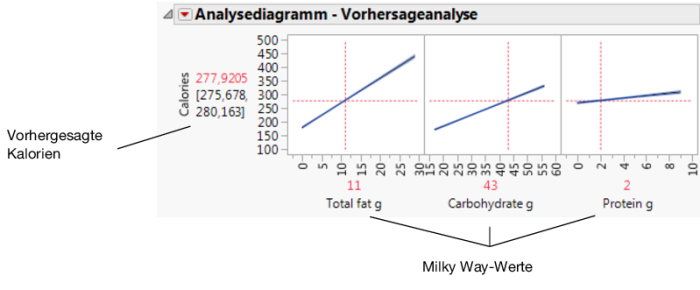
Hinweis: Weitere Informationen zur Vorhersageanalyse finden Sie im Kapitel zum Analysediagramm in Profilers.