I grafici a dispersione e altri grafici di tale tipo possono aiutare nella visualizzazione delle relazioni fra le variabili. Dopo avere visualizzato le relazioni, il passo successivo consiste nell'analizzare tali relazioni in modo da poterle descrivere numericamente. Tale descrizione numerica della relazione fra le variabili è chiamata modello. Ancora più importante, un modello prevede anche il valore medio di una variabile (Y) dal valore di un'altra variabile (X). La variabile X è chiamata anche predittore. Generalmente, questo modello è detto modello di regressione.
Con JMP, la piattaforma Stima Y rispetto a X e la piattaforma Stima modello creano modelli di regressione.
Nota: In questa sede vengono illustrate soltanto le piattaforme e le opzioni di base. Per spiegazioni su tutte le opzioni della piattaforma, consultare Basic Analysis, Essential Graphing e la documentazione elencata in Contenuto di questo capitolo.
La Tabella 5.3 Tipi di relazioni mostra i quattro tipi primari di relazioni.
|
La regressione logistica è un argomento avanzato. Consultare il capitolo Logistic Analysis in Basic Analysis.
|
Questo esempio utilizza la tabella di dati Companies.jmp, che contiene dati finanziari relativi a 32 società farmaceutiche e di informatica.
Innanzi tutto, creare un grafico a dispersione per osservare la relazione fra il numero dei dipendenti e la quantità di ricavi derivanti dalle vendite. Questo grafico a dispersione è stato creato in Creazione del grafico a dispersione nel capitolo Visualizzazione dei dati. Dopo avere nascosto ed escluso un outlier (una società con un numero significativamente elevato di dipendenti e vendite rispetto alle altre), il grafico in Figura 5.12 Grafico a dispersione di Sales ($M) rispetto a # Employ mostra il risultato.
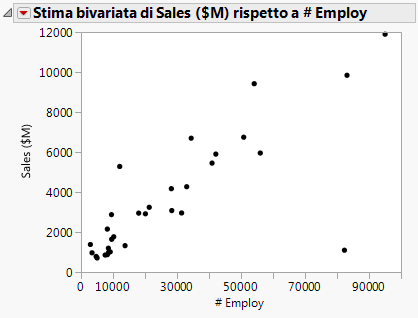
Per prevedere i ricavi derivanti dalle vendite dal numero dei dipendenti, stimare un modello di regressione. Fare clic sul triangolo rosso associato a Stima bivariata e selezionare Stima lineare. Una linea di regressione viene aggiunta al grafico a dispersione e vengono aggiunti report alla finestra dei report.
Figura 5.13 Linea di regressione
|
•
|
il p-value di <.0001
|
|
•
|
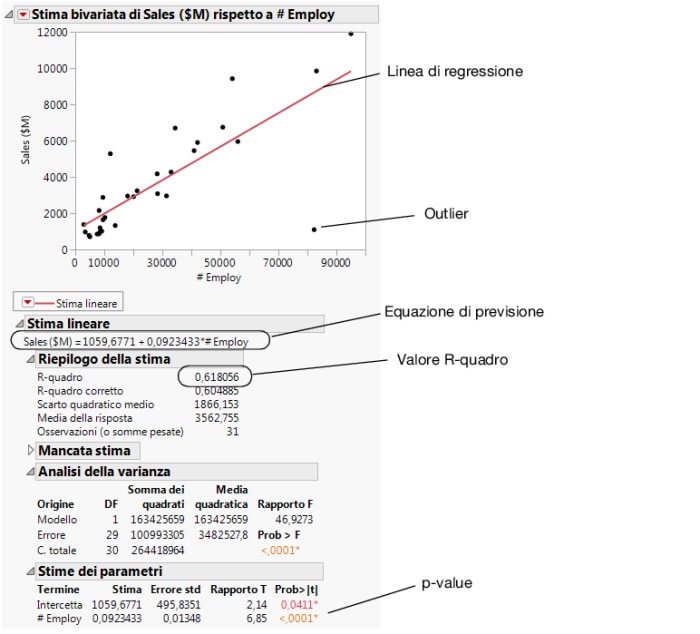
Il p-value del termine del modello #Employ è piccolo. Ciò significa che al livello di significatività di 0,05 il coefficiente di #Employ non è zero. Quindi, l'inserimento del numero dei dipendenti nel modello di previsione migliora sensibilmente la capacità di prevedere le vendite medie rispetto a un modello senza il numero dei dipendenti.
|
|
2.
|
|
3.
|
Figura 5.14 Confronto dei modelli
Utilizzando i risultati presenti in Figura 5.14 Confronto dei modelli, l'analista può trarre le seguenti conclusioni:
Questo esempio utilizza la tabella di dati Companies.jmp, che contiene dati finanziari relativi a 32 società farmaceutiche e di informatica.
|
1.
|
|
2.
|
Se la tabella di dati Companies.jmp è ancora aperta, è probabile che alcune righe siano escluse o nascoste. Per riportare le righe allo stato predefinito (tutte le righe incluse e nessuna nascosta), selezionare Righe > Cancella stati delle righe.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Fare clic su OK.
|
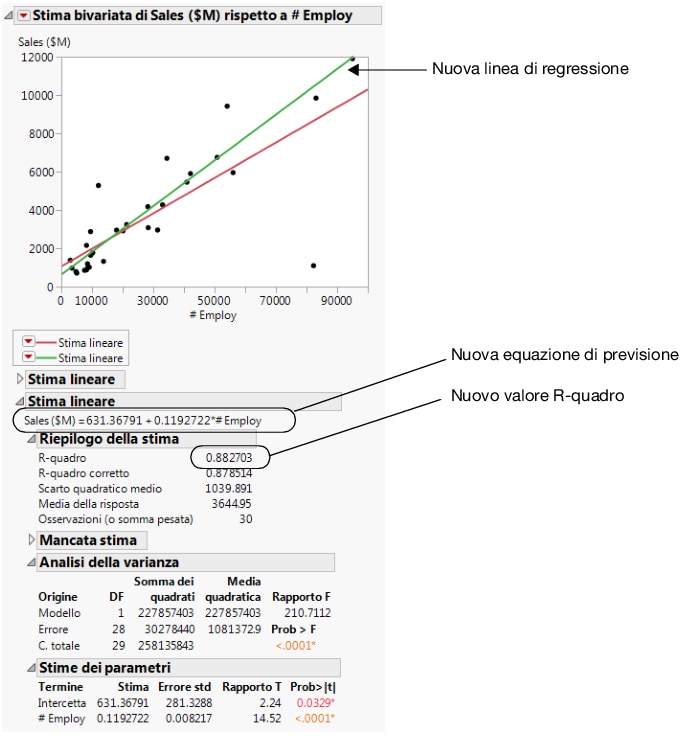
Figura 5.15 Ricavi per tipo di società
|
2.
|
|
3.
|
|
4.
|
Per ricreare il diagramma senza l'outlier, fare clic su Analisi a una via di Profits ($M) By Type e selezionare Ripeti > Ripeti analisi. È possibile chiudere la finestra originale del grafico a dispersione.
|
Figura 5.16 Grafico aggiornato
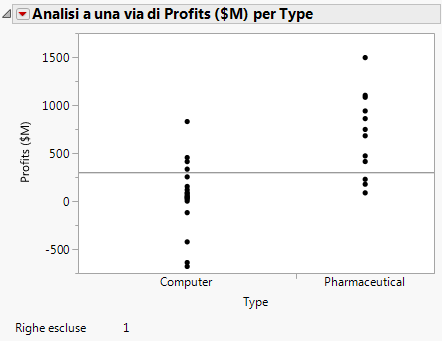
|
–
|
Opzioni di visualizzazione > Linee della media. Vengono aggiunte linee della media al grafico a dispersione.
|
|
–
|
Medie e Dev std. Viene visualizzato un report che fornisce le medie e le deviazioni standard.
|
Figura 5.17 Linee della media e report
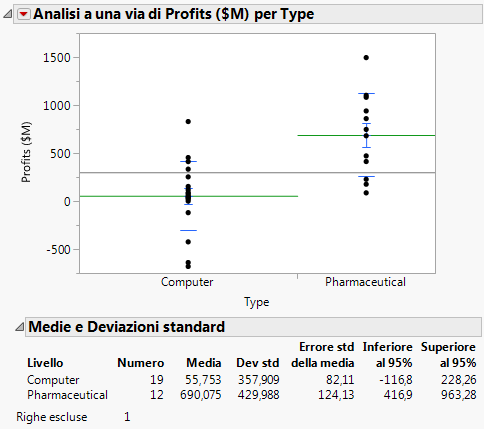
Per rispondere a tali domande, eseguire un test t a due campioni. Un test t consente di utilizzare i dati di un campione per creare inferenze sulla popolazione più ampia.
Per eseguire il test t fare clic sul triangolo rosso associato ad Analisi a una via e selezionare Medie/ANOVA/test t aggregato.
Figura 5.18 Risultati del test t
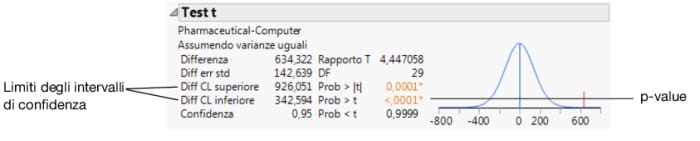
Il p-value di 0.0001 è minore del livello di significatività di 0.05, a indicare la significatività statistica. Di conseguenza, l'analista finanziario può concludere che la differenza nei ricavi medi per i dati di esempio non è dovuta unicamente a casualità. Ciò significa che nella popolazione più ampia, i ricavi medi delle società farmaceutiche sono diversi dai ricavi medi delle aziende di informatica.
Utilizzare i limiti degli intervalli di confidenza per determinare la differenza esistente nei ricavi di entrambi i tipi di società. Osservare i valori Diff CL superiore e Diff CL inferiore nella Figura 5.18 Risultati del test t. L'analista finanziario conclude che i ricavi medi delle società farmaceutiche sono, per una cifra compresa fra $343 e $926 milioni, maggiori rispetto ai ricavi medi delle aziende di informatica.
Se sono presenti le variabili categoriche X e Y, è possibile confrontare le proporzioni dei livelli all'interno della variabile Y con i livelli all'interno della variabile X.
Questo esempio continua a utilizzare la tabella di dati Companies.jmp. In Confronto di medie per una variabile, un analista finanziario ha determinato che le società farmaceutiche hanno mediamente ricavi più elevati rispetto alle aziende di informatica.
|
1.
|
|
2.
|
Se la tabella di dati Companies.jmp è ancora aperta dall'esempio precedente, è probabile che alcune righe siano escluse o nascoste. Per riportare le righe allo stato predefinito (tutte le righe incluse e nessuna nascosta), selezionare Righe > Cancella stati delle righe.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Fare clic su OK.
|
Figura 5.19 Dimensione delle società per tipo di società
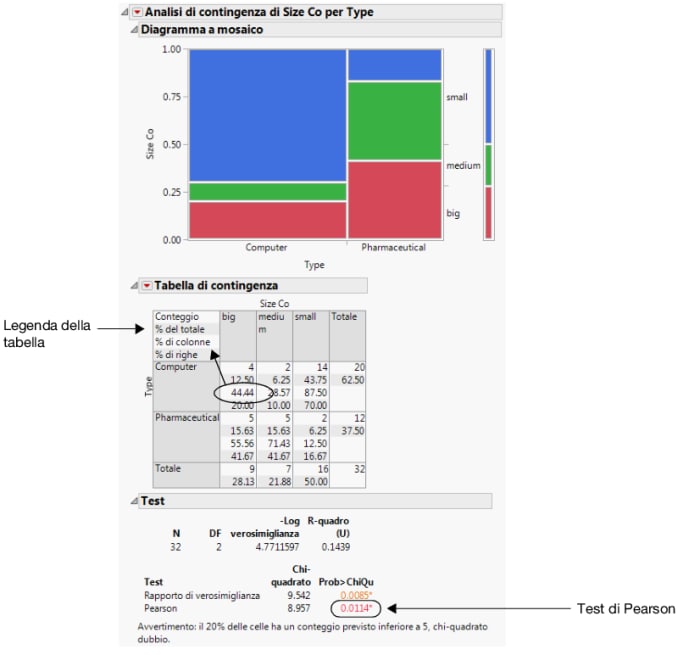
La tabella di contingenza contiene informazioni non applicabili a questo esempio. Fare clic sul triangolo rosso associato a Tabella di contingenza e deselezionare % del totale e % di colonne per rimuovere tali informazioni. La Figura 5.20 Tabella di contingenza aggiornata mostra la tabella aggiornata.
Figura 5.20 Tabella di contingenza aggiornata
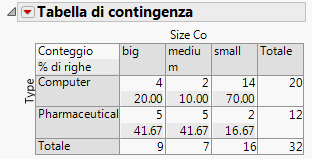
Per rispondere a questa domanda, utilizzare il p-value dal test di Pearson nel report Test (Dimensione delle società per tipo di società). Poiché il p-value di 0.011 è minore rispetto al livello di significatività di 0.05, l'analista finanziario conclude che:
La sezione Confronto di medie per una variabile, ha confrontato le medie fra i livelli di una variabile categorica. Per confrontare le medie fra i livelli di due o più variabili contemporaneamente, utilizzare la tecnica Analisi della varianza (o ANOVA).
|
•
|
Tipo (farmaceutica o di informatica)
|
|
•
|
Dimensione (piccola, media, grande)
|
|
1.
|
|
2.
|
Selezionare Grafico > Costruttore di grafici. Viene visualizzata la finestra Costruttore di grafici.
|
|
3.
|
|
4.
|
|
5.
|
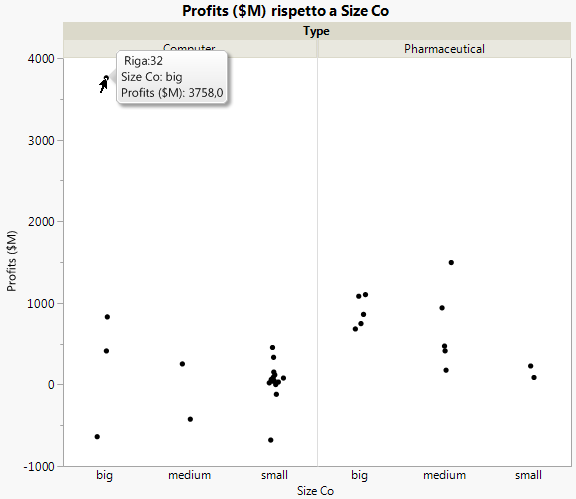
Figura 5.21 Grafico dei ricavi delle società
|
6.
|
Selezionare l'outlier, fare clic con il pulsante destro del mouse e selezionare Righe > Escludi righe. Il punto viene rimosso e la scala del grafico si aggiorna automaticamente.
|
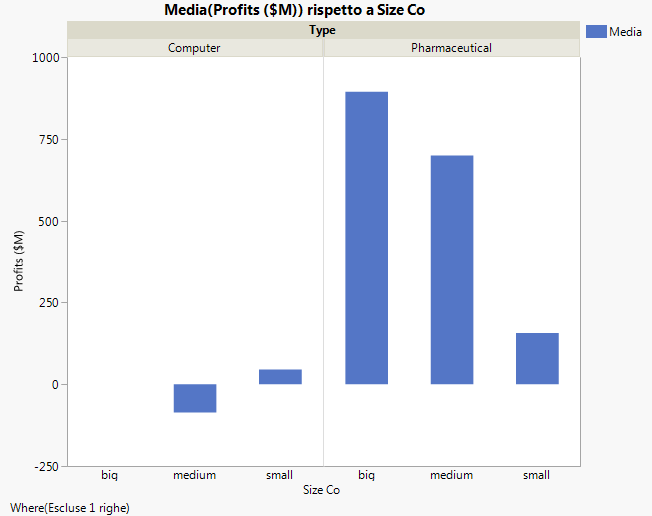
Figura 5.22 Grafico con l'outlier rimosso
|
1.
|
Ritornare alla tabella dei dati di esempio Companies.jmp in cui è stato escluso il punto di dati. Consultare Individuazione della relazione.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
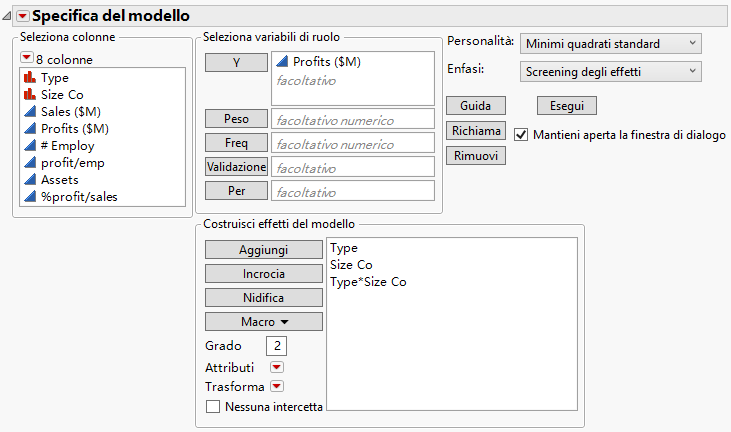
Dal menu Enfasi, selezionare Screening degli effetti.
|
|
7.
|
Selezionare l'opzione Mantieni aperta la finestra di dialogo.
|
Figura 5.23 Finestra della stima del modello completata
|
8.
|
Fare clic su Esegui. La finestra dei report mostra i risultati del modello.
|
Per stabilire se le differenze nei ricavi sono reali o dovute a casualità, esaminare il report Test degli effetti.
Nota: Per ulteriori informazioni su tutti risultati di Stima modello, consultare il capitolo Model Specification in Fitting Linear Models.
Il report Test degli effetti (Figura 5.24 Report Test degli effetti) mostra i risultati dei test statistici. Esiste un test per ognuno degli effetti inclusi nel modello nella finestra Stima modello: Type, Size Co e Type*Size Co.
Figura 5.24 Report Test degli effetti
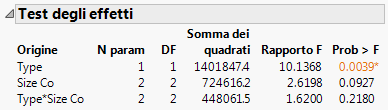
Innanzi tutto, osservare l'interazione nel modello nel test: l'effetto Type*Size Co. La Figura 5.22 Grafico con l'outlier rimosso ha dimostrato che le società farmaceutiche sembrano generare ricavi diversi in funzione delle dimensioni. Tuttavia, il test degli effetti indica che non esiste alcuna interazione fra il tipo e la dimensione per quanto riguarda i ricavi. Il p-value di 0.218 è ampio (maggiore del livello di significatività di 0.05). Di conseguenza, rimuovere tale effetto dal modello e rieseguirlo.
|
2.
|
Nella casella Costruisci effetti del modello, selezionare l'effetto Type*Size Co e fare clic su Rimuovi.
|
|
3.
|
Fare clic su Esegui.
|
Figura 5.25 Report Test degli effetti aggiornato
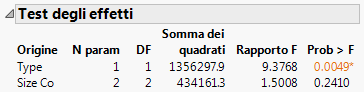
Il p-value dell'effetto Size Co è ampio e indica che non esistono differenze in base alla dimensione nella popolazione più ampia. Il p-value per l'effetto Type è piccolo e indica che le differenze rilevate nei dati fra le società farmaceutiche e di informatica non sono dovute a casualità.
La sezione Utilizzo della regressione con un predittore ha dimostrato come creare semplici modelli di regressione costituiti da una variabile predittore e da una variabile di risposta. La regressione multipla prevede la variabile di risposta media utilizzando due o più variabili predittore.
Questo esempio utilizza la tabella di dati Candy Bars.jmp, che contiene informazioni nutrizionali sulle merendine.
|
•
|
Utilizzare la regressione multipla per prevedere la variabile di risposta media usando queste tre variabili predittore.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
Fare clic su OK.
|
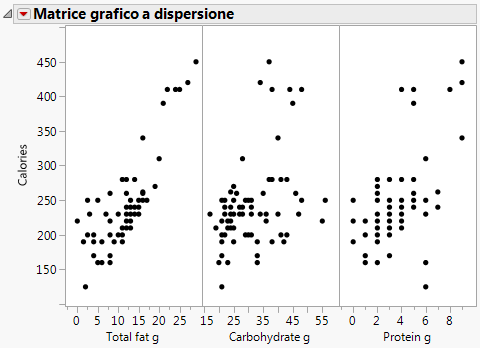
Continuare a utilizzare la tabella di dati di esempio Candy Bars.jmp.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
Accanto a Enfasi, selezionare Screening degli effetti.
|
Figura 5.27 Finestra Stima modello
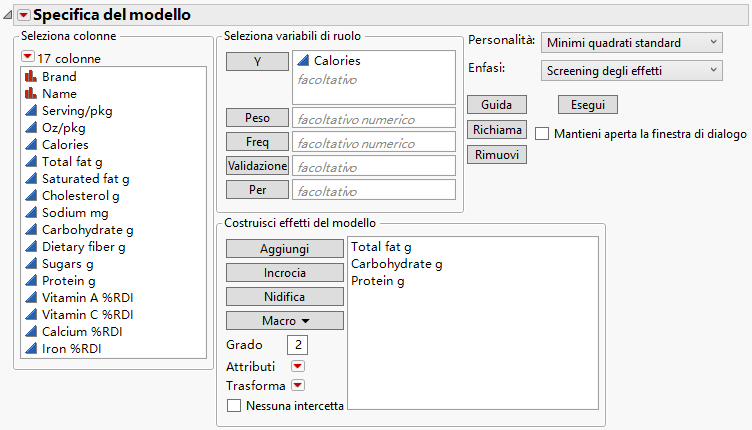
|
5.
|
Fare clic su Esegui.
|
Nota: Per ulteriori informazioni su tutti risultati del modello, consultare il capitolo Model Specification in Fitting Linear Models.
Il Grafico delle risposte osservate rispetto a risposte attese mostra le calorie osservate rispetto alle calorie previste. Quanto più i valori previsti si avvicinano ai valori osservati, tanto più i punti sul grafico a dispersione si avvicinano alla linea rossa (Figura 5.28 Grafico delle risposte osservate rispetto alle risposte attese). Poiché i punti sono tutti molto vicini alla linea, è possibile vedere che il modello prevede le calorie in base ai fattori scelti.
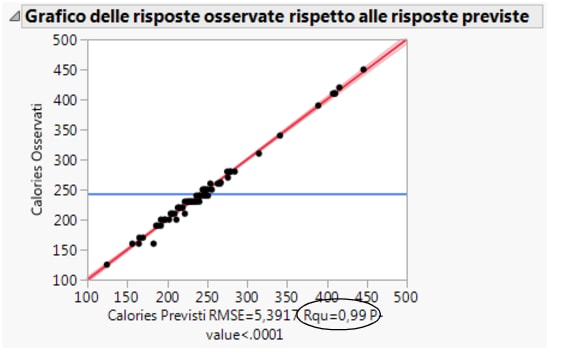
Un'altra misura della precisione del modello è il valore R-quadro (che appare sotto il grafico in Figura 5.28 Grafico delle risposte osservate rispetto alle risposte attese). Il valore R-quadro misura la percentuale di variabilità in calorie, come spiegato dal modello. Quanto più il valore si avvicina a 1 tanto più un modello fa previsioni corrette. In questo esempio, il valore R-quadro è 0.99.
|
•
|
I p-value per ogni parametro
|
Figura 5.29 Report Stime dei parametri
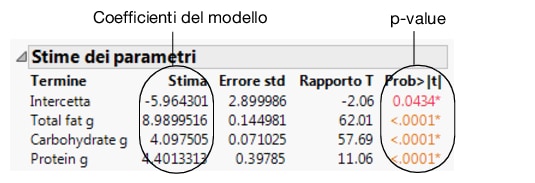
In questo esempio, i p-value sono tutti molto piccoli (<.0001). Ciò indica che tutti e tre gli effetti (grassi, carboidrati e proteine) contribuiscono significativamente alla previsione delle calorie.
Utilizzare il Profiler di previsione per osservare quali cambiamenti nei fattori influiscono sui valori previsti. Le linee del profilo mostrano la grandezza di cambiamento nelle calorie al variare dei fattori. La linea di Total fat g è la più verticale, per indicare che i cambiamenti nel grasso totale hanno gli effetti più ampi sulle calorie.
Figura 5.30 Profiler di previsione
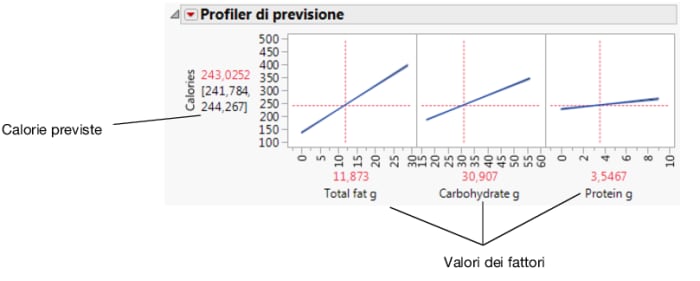
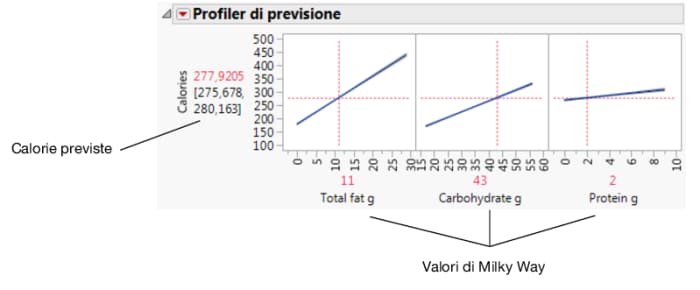
Figura 5.31 Valori dei fattori di Milky Way
Nota: Per ulteriori informazioni sul Profiler di previsione, consultare il capitolo Profiler in Profilers.