この例では、「Consumer Preferences.jmp」を使用します。このデータには、一般的な事柄に対する意見や態度が含まれています。それぞれの歯磨き時間帯(「歯磨き カンマ区切り」)に対する応答率が、「歯磨き」グループ間で同じであるかどうかを、[多重応答の検定]オプションを使って検定してみましょう。この「歯磨き」グループは、歯磨きを行う頻度で分類されているものです。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Consumer Preferences.jmp」を開きます。
|
|
2.
|
[分析]>[消費者調査]>[カテゴリカル]を選択します。
|
|
3.
|
「歯磨き カンマ区切り」を選択し、[多重]タブの[多重応答 区切り文字]をクリックします。
|
|
4.
|
「歯磨き」を選択して[X, グループ化カテゴリ]をクリックします。
|
|
5.
|
[OK]をクリックします。
|
|
6.
|
図3.8 多重応答の検定、Poisson分布
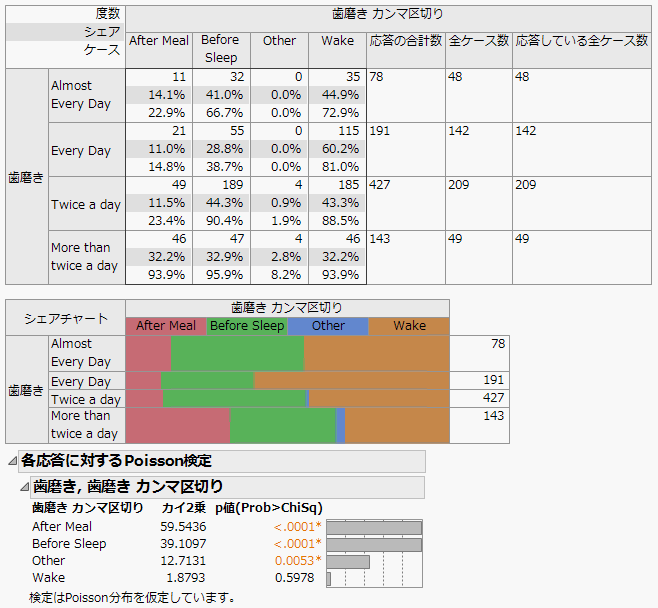
pを見ると、「After Meal(食後)」、「Before Sleep(就寝前)」、「Other(その他)」の応答率において、「歯磨き」グループ間で有意差があります。「Wake(起床後)」においては、有意差は見られません。クロス表を見ると、歯磨きの頻度とは関係なく、大半の人が起床後には歯磨きをしています。
|
7.
|
図3.9 多重応答の検定、二項分布
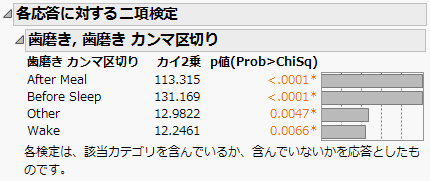
[二項分布の等質性検定]オプションでは、[Poisson分布の度数検定]よりも、必ず検定統計量が大きくなります(つまり、p値が小さくなります)。[二項分布の等質性検定]は、応答が生じた回数(起床後に歯磨きをすると答えた人の数)だけを考慮するのではなく、応答が生じなかった回数(起床後に歯磨きをすると答えなかった人の数)も考慮します。