この例では、「Consumer Preferences.jmp」を使用します。このデータには、一般的な事柄に対する意見や態度が含まれています。年齢層によって「仕事熱心である」かどうかの分布が異なるかどうかを調べてみましょう。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Consumer Preferences.jmp」を開きます。
|
|
2.
|
[分析]>[消費者調査]>[カテゴリカル]を選択します。
|
|
3.
|
「仕事熱心である」を選択して、[単純]タブの[応答]をクリックします。
|
|
4.
|
「年齢層」を選択して[X, グループ化カテゴリ]をクリックします。
|
|
5.
|
[OK]をクリックします。
|
|
6.
|
「カテゴリカル」の赤い三角ボタンをクリックして、[クロス表 転置]を選択します。
|
|
7.
|
「カテゴリカル」の赤い三角ボタンをクリックして、[セルのカイ2乗]を選択します。
|
図3.10 セルのカイ2乗
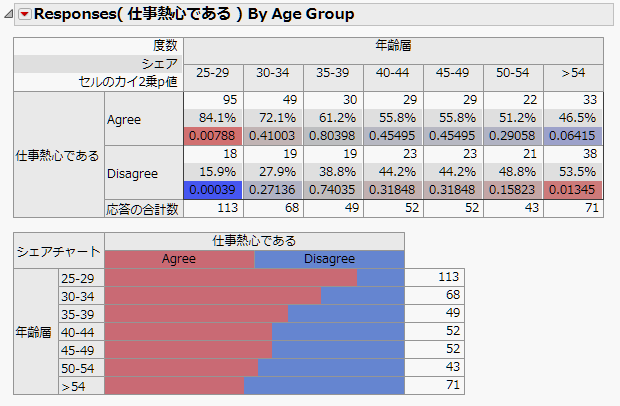
各セルにおいて、p値が小さい場合は、そのセルの観測度数と期待度数との間に有意差があることを示しています。また、各セルの色は、p値を基準にして、期待値よりも有意に度数が大きいほど濃い赤に、期待値よりも有意に度数が小さいほど濃い青に色分けされます。なお、各セルの期待度数は、観測された行和と列和から算出されます。
たとえば、25~29歳で「Agree(同意する)」と回答する人の期待度数は、(287×113)/448 = 72.4人で、実際の観測度数は95人です。そのp値は0.00788ですので、観測度数は期待度数よりも有意に大きいと言えます。「仕事熱心である」に同意する25~29歳の人数は、独立であるとの仮定から算出された期待度数よりも有意に多い、ということが分かります。