共分散分析モデルは、連続尺度の説明変数を共変量として持つ分散分析モデルです。「Drug.jmp」サンプルデータでは、列「x」が共変量です。
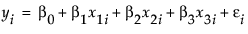
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Drug.jmp」を開きます。
|
|
2.
|
[分析]>[モデルのあてはめ]を選択します。
|
|
3.
|
「y」を選択し、[Y]をクリックします。
|
|
4.
|
|
5.
|
[実行]をクリックします。
|
レポートの先頭にある「回帰プロット」を見ると、回帰直線が平行になっています(薬剤データの共分散分析)。これは、モデルとして、傾きが等しいモデルをあてはめたからです。一元配置分散分析モデル(「薬剤」効果のみだけのモデル)と比較すると、R2乗が22.8%から67.6%に増加しています。誤差の標準偏差(RMSE)は6.07から4.0に減少しています (薬剤データの共分散分析)。また、モデル全体に対するF検定のp値は、0.03から0.0001未満に減少しています。
図4.4 薬剤データの共分散分析
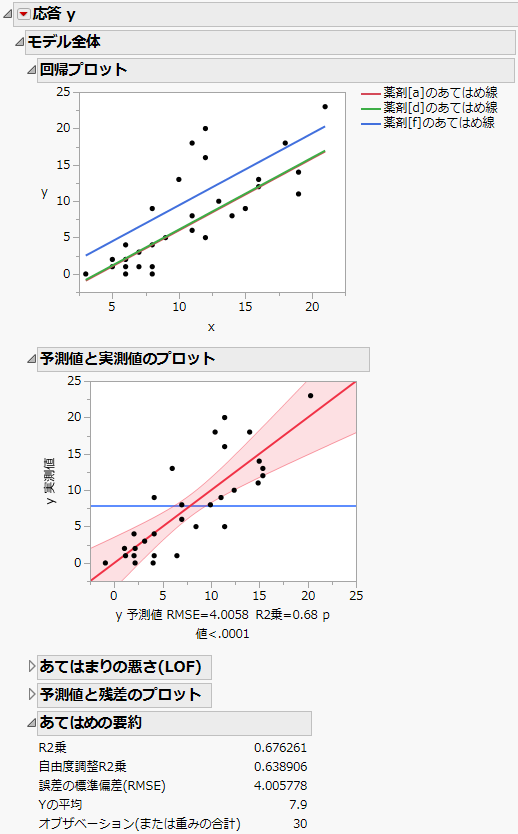
このデータは、反復している行があります。たとえば、行1と行11を見てください。両方とも、「薬剤」 = a で「x」= 11になっています。このような反復している行がある場合、それらの行の情報を用いて、純粋誤差(pure erorr)を求めることができます。そして、純粋誤差から、あてはまりの悪さ(LOF; Lack of Fit)の検定を実行できます。LOF検定が有意な場合、モデルがデータを十分に説明していないことを示唆しています。その場合、共変量の効果が直線的ではなく非線形であったり、交互作用の効果が存在していたりするなどの原因が考えられます。
この例において、共変量xは、応答の変動の多くを説明します。そのため、共変量を追加すると、誤差平方和が大幅に減少します。一方で、「薬剤」は有意でなくなります。 「薬剤」だけのモデルで説明された応答の変動の多くは、共変量によって説明されるようです。
共分散分析での各群の最小2乗平均は、群ごとの単純な標本平均とは異なります。共変量xによって調整されるためです。共分散分析での各群の最小2乗平均は、共変量xをある中立な値に固定したときの、各群における予測値です。連続尺度の説明変数の中立な値としては、その平均(ここでは10.7333)が使われます。
-2.696 - 1.185*薬剤[a] - 1.0761*薬剤[d] + 0.98718*x
-2.696 - 1.185*(1) -1.0761*(0) + 0.98718*(10.7333) = 6.71
-2.696 - 1.185*(0) -1.0761*(1) + 0.98718*(10.7333) = 6.82
-2.696 - 1.185*(-1) -1.0761*(-1) + 0.98718*(10.7333) = 10.16
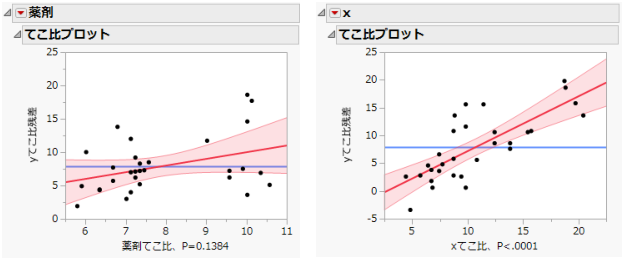
薬剤実験データのてこ比プロットは、各効果のてこ比プロットです。共変量が影響をもっているので、「薬剤」のてこ比において、「薬剤」の各グループの最小2乗平均から多少離れて点が散らばっています。
図4.5 薬剤実験データのてこ比プロット