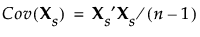|
•
|
n = 行数(標本サイズ)
|
|
•
|
p = 変数の数
|
|
•
|
推定法として[横長]を選択した場合、データは常に標準化されます。データの標準化とは、データから平均を引き、それを標準偏差で割る変換を指します。標準化したデータを、Xs(n x p行列)と記します。標準化していないデータXの相関行列は、標準化したデータの共分散行列です。よって、次のように相関係数行列は求められます。
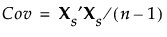
Xsは、特異値分解した行列によりUDiag(Λ)V’と表されます。この特異値分解により、固有ベクトルとXs’Xsの固有値が求められます。なお、主成分スコアはXsVによって求められます。詳細については、「統計的詳細」の付録「「線形 横長データ」の手法と特異値分解」(279ページ)を参照してください。
 疎なデータに対する手法
疎なデータに対する手法