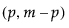測定データがサブグループ化されていない場合、サブグループの標本サイズ(n)は1になります。全体の標本サイズをm、測定対象となっている特性の数をpとします。T2統計量は、オブザベーションごとに計算され、プロットされます。T2統計量と上側管理限界(UCL; Upper Control Limit)の計算は、目標統計量の元のデータによって異なります。フェーズI管理図の管理限界は、管理図上にプロットされたのと同じデータから計算されます。フェーズII管理図の管理限界は、履歴データから求めた目標統計量に基づいて計算されます。HotellingのT2管理図のT2統計量と管理限界の計算方法について詳しくは、Montgomery(2013)を参照してください。
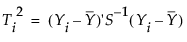
Yは、p個の変数の標本平均の列ベクトル。
S-1は、標本共分散行列の逆行列。
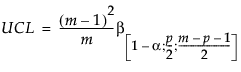
p = 変数(列)の数
m = オブザベーションの数
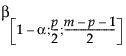 =パラメータが
=パラメータが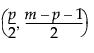 であるベータ分布の(1–α)分位点
であるベータ分布の(1–α)分位点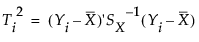
X̅は、履歴データセットから求めたp個の変数の標本平均の列ベクトル。
フェーズIIの管理限界を計算する際、新しいオブザベーションは履歴データからは独立しています。この場合、上側管理限界(UCL)はF分布の関数となり、目標値の計算に使用した履歴データセット中のオブザベーション数によってその定義は異なります。UCLは次式で定義されます。
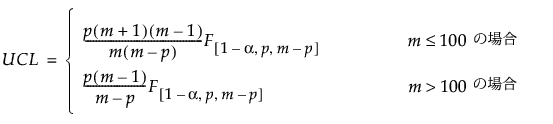
p = 変数(列)の数
m = 履歴データにおけるオブザベーションの数
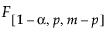 =
=