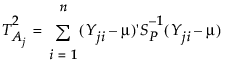p個の変数を監視し、標本サイズnが1より大きいサブグループがm個得られたとします。T2統計量は、サブグループごとに計算され、プロットされます。T2統計量と上側管理限界(UCL)の計算は、目標統計量を求めたデータの種類によって異なります。フェーズI管理図の管理限界は、管理図上にプロットされたのと同じデータから計算されます。フェーズII管理図の管理限界は、履歴データセットから求めた目標統計量に基づいて計算されます。HotellingのT2管理図のT2統計量と管理限界の計算方法について詳しくは、Montgomery(2013)を参照してください。
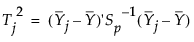
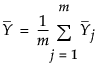 はサブグループ平均の平均値。
はサブグループ平均の平均値。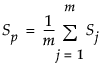 は、群内共分散行列の平均として求めた、プールした共分散行列。
は、群内共分散行列の平均として求めた、プールした共分散行列。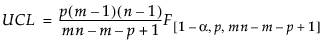
p = 変数(列)の数
n = 各サブグループの標本サイズ
m = サブグループの数
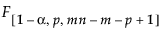 =
= 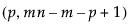
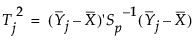
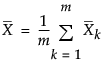 は、オブザベーションの全体平均。
は、オブザベーションの全体平均。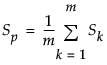 は、群内共分散行列の平均として求めた、プールした共分散行列。
は、群内共分散行列の平均として求めた、プールした共分散行列。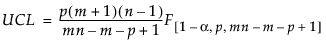
p = 変数(列)の数
n = サブグループの標本サイズ
m = 履歴データセット内のサブグループの数
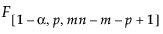 =
= 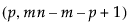
独立した正規分布に従うmn個のオブザベーションから成る標本を、標本サイズがnの合理的なサブグループm個にグループ化したとします。ここで、j番目のサブグループにおける平均Yjと目標値との距離をT2Mと表します。(このT2Mは、前節で求めた、サブグループ化されたデータにおけるT2です。)一方、各サブグループの個々のデータに関して、群内変動や、全体的な変動を表す、T2統計量も定義できます。これら3つのT2統計量には、平方和のように加算性があります。具体的には、m個のサブグループのそれぞれについて、次のような関係が成り立ちます。
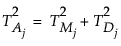
j番目のサブグループの目標値からの距離は、次のように定義されます。
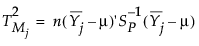
j番目のサブグループにおける群内変動は、次のように定義されます。
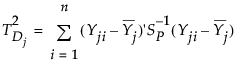
j番目のサブグループにおける全体的な変動は、次のように定義されます。