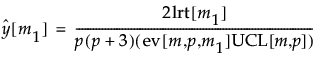ここでは、Sullivan and Woodall(2000)に沿って説明します。
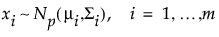
|
•
|
|
•
|
|
–
|
|
–
|
|
–
|
ここで採用されている尤度比検定の枠組みは、平均ベクトルと共分散行列のいずれか、または両方に生じた変化を検出するものです。尤度比検定統計量から、上側管理限界の近似値が1となるような、管理図の統計量が計算されます。この管理図の統計量は、m1の可能なすべての値に対してプロットされます。管理図の統計量が上側管理限界である1を超えた場合、それは、シフトが生じたことを示唆します。シフトが1つしか生じていないと仮定すると、そのシフトは、管理図の統計量が最大であるオブザベーションの直後に始まったと考えられます。
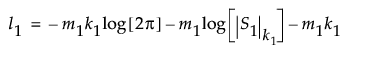
l1の等式では、次のような表記を使用しています。
|
•
|
|
•
|
|
•
|
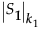 という表記は、行列
という表記は、行列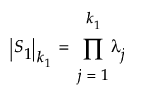
後に続くm2 = m - m1個のオブザベーションの対数尤度関数の2倍の最大値をl2とし、m個すべてのオブザベーションの対数尤度の2倍の最大値をl0とします。l2とl0は、どちらもl1と同様の計算式で求められます。
尤度比検定統計量は、l1 + l2の和をl0と比較します。l1 + l2の和は、m1でシフトが生じていると仮定したときの対数尤度の2倍です。l0の値は、シフトがないと仮定したときの対数尤度の2倍です。l0がl1 + l2を大幅に下回る場合、工程は不安定な状態にあると考えられます。
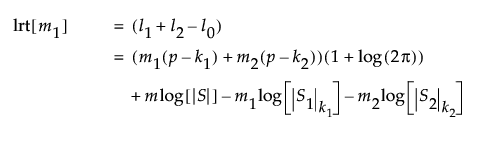
シミュレーションから、lrt[m1]の期待値は、期間内におけるオブザベーションの位置によって異なり、さらに、特にpとmに依存することがわかっています。Sullivan and Woodall(2000)を参照してください。
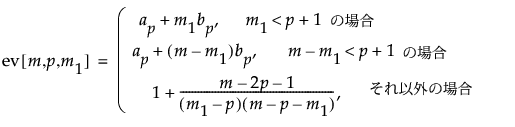
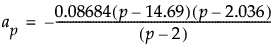
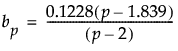
メモ: この近似式は、p > 12またはm < (2p + 4)の場合には近似がよくありません。そのような場合は、上記の近似式によってではなく、乱数シミュレーションによって近似の期待値を求めるべきです。
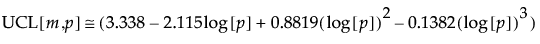
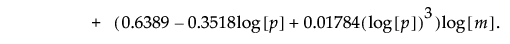
管理図の統計量は、尤度比検定統計量の対数の2倍を、p(p + 3)、その期待値の近似値、および、その管理限界の近似値で割ったものとして定義されています。管理限界の近似値で割ることにより、算出された管理図の統計量の上側管理限界は1となります。最終的に、管理図の統計量は次式で計算されます。