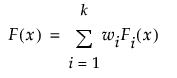
ここで、Fi(x) は混合する確率分布の累積分布関数、kは混合する確率分布の個数、wiは合計が1になる正の重みです。[混合分布のあてはめ]オプションで実行される推定では、各クラスター(かたまり)における分布がそれぞれ累積分布関数Fi(x)で表され、それらのクラスターを混合したものからデータが生成された、と仮定しています。混合分布のパラメータを推定するだけではなく、ある観測値が特定のクラスターから生成された確率も算出できます。
混合分布を推定するためには反復計算が使われていますが、その反復計算の開始値の求め方は、「開始値の手法」のオプションで変更できます。ここではk個で構成された混合分布を推定するとします。次の3つの手法があります。
|
•
|
[分離できるクラスター]は、各分布は一部の観測値に対して他の観測値よりもより強く影響していると仮定します。[分離できるクラスター]の場合、k個の分布における密度関数がそれぞれ識別可能な最頻値を持ち、クラスターを形成していると仮定されます。
|
|
•
|
[重なったクラスター]は、[単一のクラスター]と[分離できるクラスター]の中間的な状況を仮定します。つまり、あるクラスターに対して、密度関数が大きくなっている分布もありますが、その他の分布も一緒に影響していると仮定します。このオプションでは、データにm個のクラスターがあると仮定されます。ここでmは、分布の個数kより少ない数です。
|
反復計算の開始値を求める手法を選択します。第 “混合分布の推定における開始値”を参照してください。
[実行]をクリックすると、指定されている混合分布があてはめられます。「モデルリスト」にはあてはめた混合分布が追加され、また、混合分布の名前をもつレポートが追加されます。
「モデルリスト」レポートには、あてはめた混合分布が一覧表示されます。また、パラメータの個数、観測値の個数、AICc、対数尤度の-2倍、BICといった統計量が混合分布ごとに表示されます。これらの統計量の詳細については、『基本的な回帰モデル』の付録「統計的詳細」を参照してください。
|
•
|
「比較の規準」オプションは、「モデルリスト」のモデルの順序には影響しません。
|
パラメータ推定値は、混合されている各分布に対して求められます。「パラメータ」列には、「割合 <i>」というパラメータも含まれます。ここで、i = 1、2、..、k-1です。これらは、混合分布における重みwiの推定値です。重みの合計は1なので、k番目の重みはk - 1個の重みから計算できます。
因子を設定するためのウィンドウが表示されます。因子の現在の設定に特定の値を指定したり、その設定をロックしたり、プロット点の数を変更したりできます。詳細については、『プロファイル機能』の「プロファイル」章を参照してください。
プロファイル設定、スクリプト、プロファイルの連動に関連するオプションが用意されています。詳細については、『プロファイル機能』の「プロファイル」章を参照してください。
|
1.
|
|
2.
|
[分析]>[信頼性/生存時間分析]>[寿命の一変量]を選択します。
|
|
3.
|
「Y1」を[Y, イベントまでの時間]に指定します。
|
|
4.
|
[OK]をクリックします。
|
|
5.
|
「寿命の一変量」の赤い三角ボタンメニューから、[混合分布のあてはめ]を選択します。
|
|
6.
|
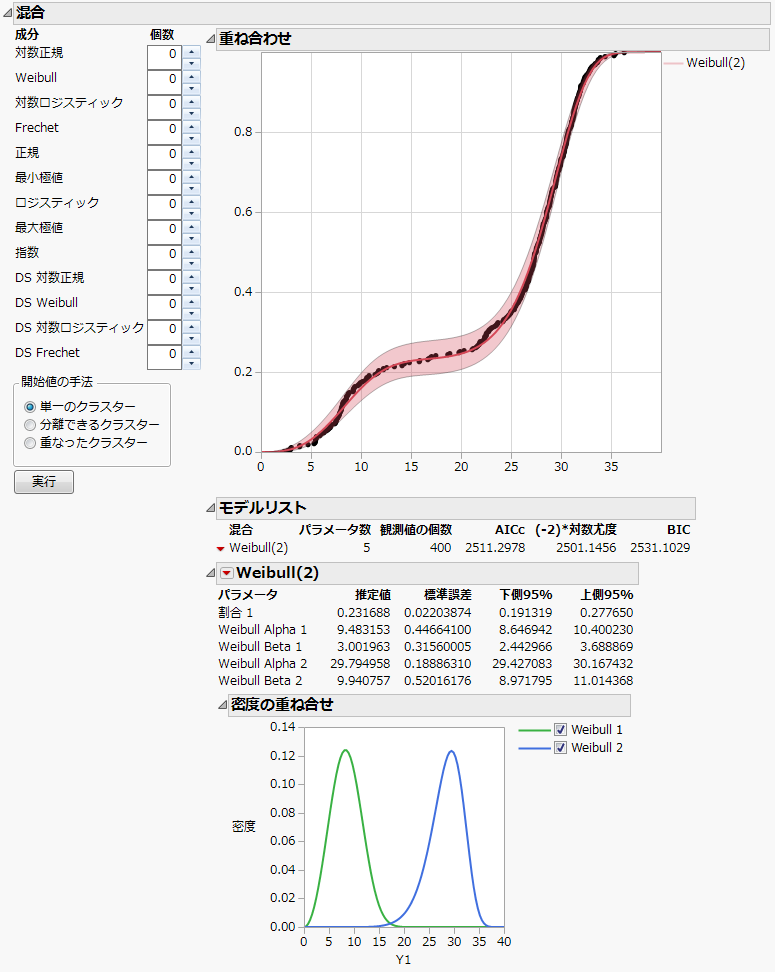
「Weibull」の横の「個数」ボックスに「2」とタイプします。
|
|
7.
|
「開始値の手法」パネルで[分離できるクラスター]を選択します。
|
|
8.
|
[実行]をクリックします。
|
図3.10 「Weibull (2)」の混合分布のあてはめ
|
9.
|
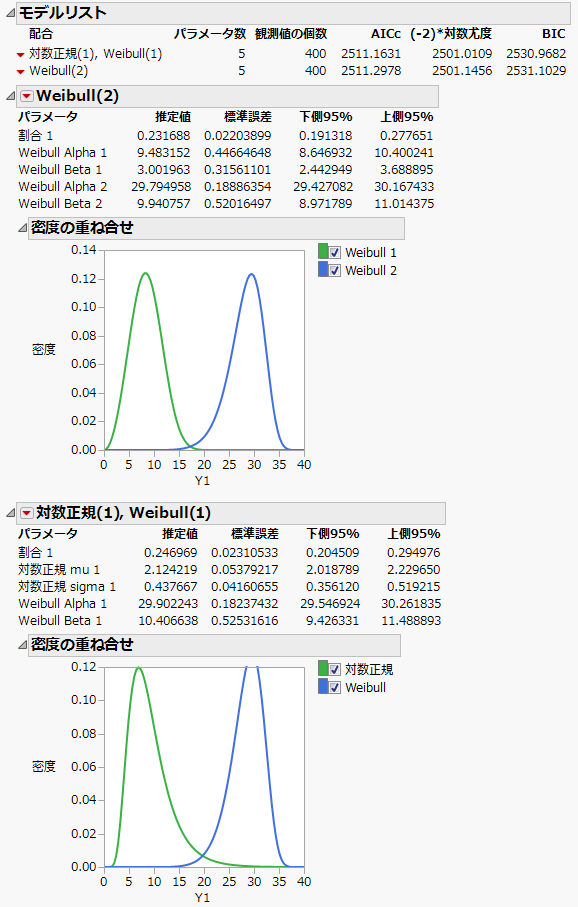
「対数正規」の横に「1」と、また、「Weibull」の横に「1」と入力します。
|
|
10.
|
[実行]をクリックします。
|
|
1.
|
「対数正規(1), Weibull(1)」というアウトラインにある赤い三角ボタンのメニューから、[予測の保存]を選択します。
|
|
2.
|
[分析]>[一変量の分布]を選択します。
|
|
3.
|
「列の選択」リストからこの2つの列を選択し、[Y,列]をクリックします。
|
|
4.
|
[ヒストグラムのみ]にチェックマークをつけます。
|
|
5.
|
[OK]をクリックします。
|
|
6.
|
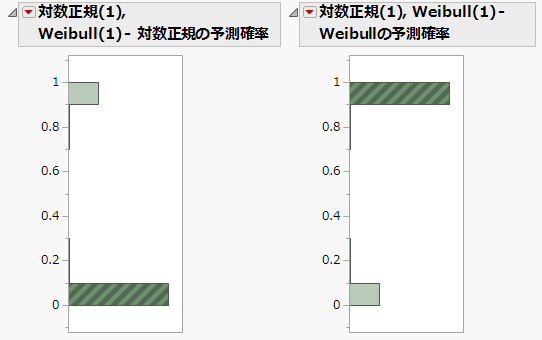
「対数正規(1), Weibull(1) - Weibull の予測確率」のヒストグラムで、1に近い値に対応する棒をクリックします。
|
図3.12 混合確率のヒストグラム