Import Data
Upon importing, JMP converts file types such as text files and Microsoft Excel files to the data table format. On Windows, JMP relies on three-letter filename extensions to identify the type of file and how to interpret its contents. Here are some examples of filename extensions identified by JMP:
Open( "$SAMPLE_IMPORT_DATA/Bigclass.xlsx" ); // Microsoft Excel file
Open( "$SAMPLE_IMPORT_DATA/Bigclass.txt" ); // text file
Open( "$SAMPLE_IMPORT_DATA/Carpoll.xpt" ); // SAS transport file
On macOS, JMP relies on the macOS Type and Creator codes (if present) and secondarily on three-letter filename extensions. Be sure to add the file extension before importing the file on macOS.
• Type and Creator codes are invisible data that enable the Finder to display a file with the correct icon corresponding to the application that created it.
• Files with generic icons should have the filename extensions (as with files created on other operating system).
Open( "$SAMPLE_IMPORT_DATA/Bigclass.txt", text );
Additional supported formats include .csv, .jsl, .dat, .tsv, and .jrn.
For more detailed information about import options, see File Functions in the JSL Syntax Reference.
Import Multiple Files
When you save a script from the Multiple File Import (MFI) window into a script window, you get a compact form of the script that includes all of the parameters, default or otherwise, as messages. You could pare down the script as follows:
mfi = Multiple File Import(
<<Set Folder( "$SAMPLE_IMPORT_DATA" ),
<<Set Name Filter( "UN*.csv" ), // import files with this name
<<Set Add File Name Column( 1 ) // display the file names in a column
)
<<Import Data();
Note the slight distinction between the following expressions:
mfi = Multiple File Import();
mfi holds the Multiple File Import object.
dtlist = Multiple File Import(…) << Import Data;
dtlist holds the list of files produced by sending the Import Data message to the MFI object. The MFI object is gone because it was not stored in a variable or window. You can keep the MFI object by sending Create Window to it or storing the object in a variable, such as mfi, and by sending messages such as Import Data to that variable.
Create Window() can be useful for debugging. The window is visible and the MFI object is available. Run the following lines one at a time to see it:
mfi = Multiple File Import();
mfi <<Create Window;
mfi <<Set Folder( "$DESKTOP" );
Here’s an example of using a callback function to get a list of imported files after the user clicks Import on the Multiple File Import window.
Delete Directory( "$TEMP/test" );
Create Directory( "$TEMP/test" );
Save Text File( "$TEMP/test/argylesocks1.txt", "a1\!n1" ); // make some
Save Text File( "$TEMP/test/argylesocks2.txt", "a2\!n1" ); // data
global:importedFiles={};
mfi = Multiple File Import( // make an MFI object
<<Set Folder( "$TEMP/test/" ),
<<Set Name Filter( "argylesocks?.txt;" ),
<<Set Name Enable( 1 ),
<<Set Add File Name Column( 1 ),
<<Set Import Callback(
Function( {this, files}, // the callback function
global:importedFiles = files;
/* optional: omit Close Window to keep the Multiple File Import window open so that the user can modify the settings. */
win << Close Window;
)
)
);
win = mfi << Create Window; // open the window
While(
Try(
win << Parent;
1;
,
0
),
Wait( 1 )
); // wait for the dialog to close
Show( global:importedFiles ); // proceed
Notes:
• See Import Multiple Files in Using JMP for more information about MFI.
• See Import Images from a Directory for more information about using MFI to import images from a web page into a data table.
Import a PDF File
In a PDF file, data is laid out in tables. JMP auto-detects these tables to determine where the rows and columns begin and end.
You write scripts that specify the dimensions of each table on each page, the number of column headers, whether the tables should be concatenated or individual, and more.
Note: A PDF file consists of tables that contain data. In the PDF preview of the PDF Import Wizard, the tables are outlined and selected on each page.
The following options are available for importing a PDF file:
Open( "PDF file path" ),
Tables(
Table( "data table name",
Add Rows( Header Rows( number ),
(Rect( left, right, top, bottom ),
Page( number ), Row Borders(), Column Borders())) |
Tables( Combine( All | Matching Headers | None),
Minimum Rows( number ), Minimum Columns(#))))
| PDF wizard );
Concatenate Tables Into One Data Table
This section shows how to import and concatenate the tables into one data table. The script that you create appears in a Source variable in the final data table, so you can run it again anytime.For this example, Figure 9.1 shows the sample import data file called Food Distribution.pdf, which contains one table per page.
Figure 9.1 Initial PDF File
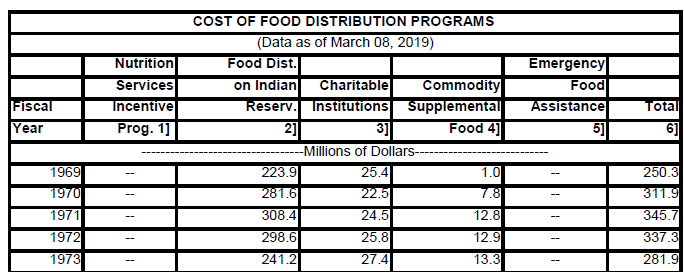
Open( "$SAMPLE_IMPORT_DATA/Food Distribution.pdf",PDF Tables(
Table( // import tables into one tableTable Name( "Food Distribution" ), // data table name
Add Rows( // rows on page 1Header Rows( 7 ), // number of header rows
Page( 1 ),Rect( 0.6922, 0.7155, 7.2842, 10.1124 ) // size of the table
), // rows and specifications on page 2Add Rows( Page( 2 ), Rect( 0.6922, 0.7156, 7.2842, 10.0708 ) )
)
)
);
Tip: Import a PDF file in the PDF Import Wizard and copy the script from the Source variable into a standalone script. This is a quick way to get the settings and avoid having to guess at the Rect settings.
Save as Individual Data Tables
The following syntax shows how to save tables in a PDF file into individual data tables. Each resulting data table contains a Source script like the one below.
Open(
"PDF file path",PDF Tables(
Table(
Table Name( "data table name" ),Add Rows( Page( number ), Rect( left, right, top, bottom ) )
)
)
);
Concatenate Data Based on Column Headers
The following example shows how to concatenate data when column names on each page match.
Figure 9.2 Data with Matching Column Headers on each Page
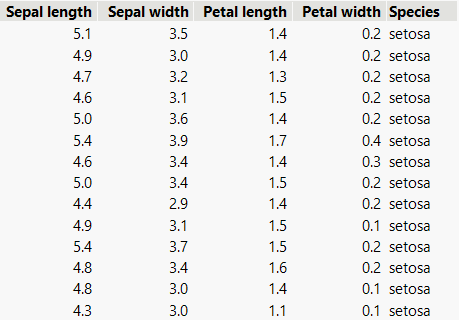
pdftable = Open( "$SAMPLE_IMPORT_DATA/Iris.pdf",PDF All Tables( Combine( Matching Headers ) )
);
Figure 9.3 Final Data Table
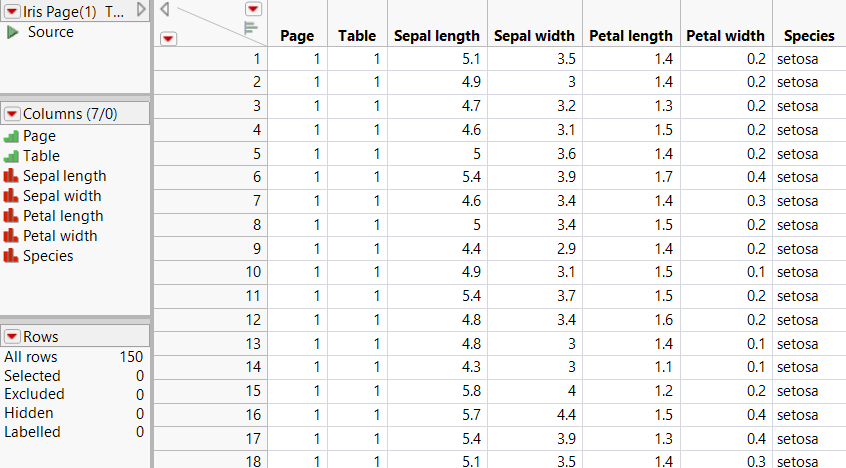
Import PDF Pages that Contain Multiple Tables
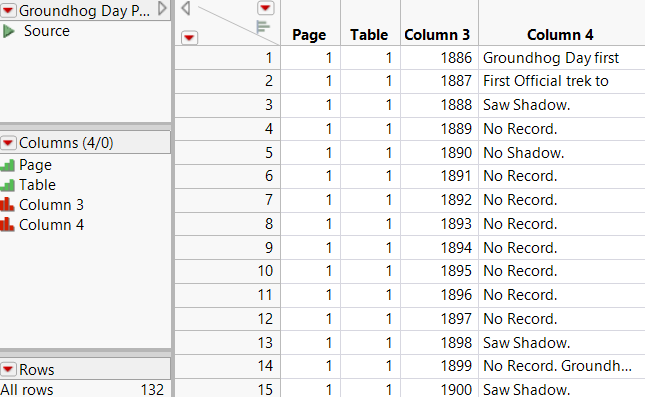
A PDF file might contain data divided into multiple columns on each page. Figure 9.4 shows the sample import data PDF file called Groundhog Day Predictions.pdf, which contains multiple tables per page.
Figure 9.4 Multiple Columns on a Page
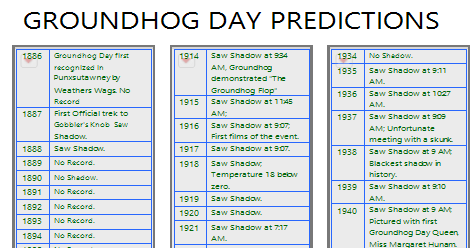
The following script imports all columns into a single data table.
Open( "$SAMPLE_IMPORT_DATA/Groundhog Day Predictions.pdf",PDF Tables(
Table(
Table Name( "Groundhog Day Predictions" ), // specifications for page 1Add Rows( Page( 1 ), Rect( 0.9726, 1.4325, 3.0351, 9.9974 ) ),
Add Rows( Page( 1 ), Rect( 3.3063, 1.4325, 5.3688, 9.9608 ) ),
Add Rows( Page( 1 ), Rect( 5.6399, 1.4325, 7.7025, 8.7925 ) ),
// specifications for page 2Add Rows( Page( 2 ), Rect( 0.9726, 1.4325, 3.0351, 9.9441 ) ),
Add Rows( Page( 2 ), Rect( 3.3063, 1.4325, 5.3688, 9.9274 ) ),
Add Rows( Page( 2 ), Rect( 5.6399, 1.4325, 7.7025, 8.8225 ) ),
// specifications for page 3Add Rows( Page( 3 ), Rect( 0.9726, 1.4325, 3.0351, 7.6404 ) ),
Add Rows( Page( 3 ), Rect( 3.3063, 1.4325, 5.3688, 7.1254 ) ),
Add Rows( Page( 3 ), Rect( 5.6399, 1.4325, 7.7025, 7.4721 ) )
)
)
);
Figure 9.5 Final Data Table
Export Data to a Text String
You can export data from a PDF file into a text string. You might want to do this to extract a pattern from the data.
Here is a basic example that imports all text from the Iris.pdf sample import data.
Open( "$SAMPLE_IMPORT_DATA/Iris.pdf", PDF text );
The following script finds the word “Figure” followed by a space, a digit, a period, and another digit and then prints the data to the log.
txt = Open( "$JMP_HOME/Documentation/JMP Documentation Library.pdf", PDFText() );
figures = {};For( page = 1, page < N Items( txt ), page++,
// search for the stringnext = Regex Match( txt[page], "Figure\s+\d+\.\d+", "" );
While( N Items( next ) > 0,
figures = Insert( figures, next ); // extract the stringnext = Regex Match( txt[page], "Figure\s+\d+\.\d+", "" );
);
);
Print( figures );{"Figure 2.1", "Figure 2.2", "Figure 2.3", "Figure 2.4", "Figure 2.4", "Figure 2.4", "Figure 2.4", "Figure 2.5", "Figure 2.6", "Figure 2.7", "Figure 2.8", "Figure 2.9", "Figure 2.10", "Figure 2.10", ...}
Import Data from a Text File
The Import Settings in the Text Data Files preferences determine how text files are imported. For example, column names begin on line one and data begin on line two by default. To use different settings, specify the import settings as Open() options in your script.
The default Import Settings and your custom import settings are saved in the data table Source script, so you can reimport the data using the same settings. However, the default Import Settings are optional in the script.
The following Open() options are available:
/* Charset options: "Best Guess", "utf-8", "utf-16", "us-ascii", "windows-1252", "x-max-roman", "x-mac-japanese", "shift-jis", "euc-jp", "utf-16be", "gb2312" */
CharSet("option")Number of Columns(Number)
/* colType is Character|Numeric
colWidth is an integer specifying the width of the column */
Columns(colName=colType(colWidth),... )
Treat Empty Columns as Numeric(Boolean)
Scan Whole File(Boolean)
End Of Field(Tab|Space|Comma|Semicolon|Other|None)
EOF Other("char")End Of Line(CRLF|CR|LF|Semicolon|Other)
EOL Other("Char")Strip Quotes|Strip Enclosing Quotes(Boolean)
Labels | Table Contains Column Headers(Boolean)
Year Rule | Two digit year rule ("Decade Start")Column Names Start | Column Names are on line(Number)
Data Starts | Data Starts on Line(Number)
Lines to Read(Number)
Use Apostrophe as Quotation Mark
CompressNumericColumns(Boolean)
CompressCharacterColumns(Boolean)
CompressAllowListCheck(Boolean)
The following script opens a text file of comma-delimited text, which includes no column names. The script defines the column names and the column widths.
Open( "$SAMPLE_IMPORT_DATA/EOF_comma.txt",End of Field( comma ),
Labels( 0 ),Columns(
name = Character( 12 ), age = Numeric( 5 ), sex = Character( 5 ), height = Numeric( 3 ), weight = Numeric( 3 ))
);
Here is an example of opening a text file in which the field separator is a space and the text file does not contain column headings:
Open( "$SAMPLE_IMPORT_DATA/EOF_space.txt", Labels( 0 ),End of Field( Space )
);
In the preceding example of a text file with space field separators, JMP can select the best file format so that you do not have to specify the labels or separator:
Open( "$SAMPLE_IMPORT_DATA/EOF_space.txt",Import Settings( Guess File Format() )
);
To set the import options interactively, include the Text Wizard argument. A preview of the text file opens in the text import window.
Open( "$SAMPLE_IMPORT_DATA/EOF_space.txt", "Text Wizard" );
The following sections describe each argument in more detail. For more information about import options, see File Functions in the JSL Syntax Reference.
Number of Columns
Specifies the total number of columns in the source file. This option is important if data is not clearly delimited.
Columns
Identifies column names, column types, and column widths with a Columns argument as shown in the preceding examples.
If you specify settings for a column other than the first column in the file, you must also specify settings for all the columns that precede it. Suppose that you want to open a text file that has four columns (name, sex, and age, and ID, in that order). age is a numeric column, and the width should be 5. You must also set the name and sex column types and widths, and list them in the same order:
Columns(
name = Character( 15 ),
sex = Character( 5 ),
age = Numeric( 5 )
);
You are not required to provide settings for any columns that follow the one that you want to set (in this example, ID).
After the data is imported, you use the modeling type for a column. See Set or Get Data and Modeling Types.
Note: Most of the following arguments are defined in the JMP preferences. To override the preference, include the corresponding argument described below in your import scripts.
Treat Empty Columns as Numeric
Imports columns of missing data as numeric rather than character data. A period, Unicode dot, NaN, or a blank string are possible missing value indicators. This is a Boolean value. The default value is false.
Scan Whole File
Specifies how long JMP scans the file to determine data types for the columns. This is a Boolean value. The default value is true; the entire file is scanned until the data type is determined. To import large files, consider setting the value to false, which scans the file for five seconds.
Strip Quotes | Strip Enclosing Quotes
Specifies whether to include or remove the double quotation marks ( " ) that surround string values. This is a Boolean value. The default value is true.
For example, suppose that the field delimiter is a space:
• John Doe is interpreted as two separate strings (John and Doe).
• "John Doe" is interpreted as a single string. Most programs (including JMP) read a quotation mark and ignore other field delimiters until the second quotation occurs.
• If you include Strip Quotes(1), "John Doe" is interpreted as John Doe (one string without quotation marks).
Note that many word processors have a “smart quotation marks” feature that automatically converts double quotation marks ( " ) into left and right curled quotation marks ( “ ” ). Smart quotation marks are interpreted literally as characters when the text file is imported, even when JMP strips double quotation marks.
End of Line(CR | LF | CRLF | Semicolon | Other)
Specifies the character or characters that separate rows. The choices are as follows:
• CR for carriage returns (typical for text files created on macOS up to version 9)
• LF for linefeeds (typical for UNIX and Mac OS X text files)
• CRLF for both a carriage return followed by a linefeed (typical for Windows text files).
All three characters are line delimiters by default.
Use the Other option to use an additional character for the row separator, which you must specify in the EOLOther argument. JMP interprets either this character or the default character as a row separator.
End of Field(Tab | Space | Spaces | Comma | Semicolon | Other | None)
Specifies the character or characters used to separate fields.
Notes:
• The default field delimiter is Tab.
• Use the Other option to use a different character for the field separator, which you must specify in the EOFOther argument.
• The Space option uses a single space as a delimiter.
• The Spaces option uses two or more spaces.
EOFOther, EOLOther
Specifies the character or characters used to separate fields or rows. For example, EOLOther("*") indicates that an asterisk separates rows in the text file.
Labels | Table Contains Column Headers
Indicates whether the first line of the text file contains column names. This is a Boolean value. The default value is true.
Year Rule | Two Digit Year Rule
Specifies how to import two-digit year values. If the earliest date is 1979, specify "1970". If the earliest date is 2001, specify "20xx".
Column Names Start | Column Names Are on Line
Specifies the starting line for column names. The following example specifies that the column names in the text file start on line three.
Open( "$SAMPLE_IMPORT_DATA/Animals_line3.txt",Columns(
Column( "species", Character, "Nominal" ),
Column( "subject", Numeric, "Continuous", Format( "Best", 10 ) ),
Column( "miles", Numeric, "Continuous", Format( "Best", 10 ) ),
Column( "season", Character, "Nominal" )
),
Column Names Start( 3 ));
Data Starts | Data Starts on Line
Specifies the starting line for data.
The following example specifies that the data in the text file start on line five.
Open( "$SAMPLE_IMPORT_DATA/Bigclass_L.txt",Columns(
Column( "name", Character, "Nominal" ),
Column( "age", Numeric, "Continuous", Format( "Best", 10 ) ),
Column( "sex", Character, "Nominal" ),
Column( "height", Numeric, "Continuous", Format( "Best", 10 ) ),
Column( "weight", Numeric, "Continuous", Format( "Best", 10 ) )
),
Data Starts( 5 ));
Lines to Read
Specifies the number of lines to include in the data table. JMP starts counting after column names are read.
The following example includes only the first 10 lines in the data table.
Open(
"$SAMPLE_IMPORT_DATA/Bigclass_L.txt",Columns(
Column( "name", Character, "Nominal"),
Column( "age", Numeric, "Continuous", Format( "Best", 10 ) ),
Column( "sex", Character, "Nominal" ),
Column( "height", Numeric, "Continuous", Format( "Best", 10 ) ),
Column( "weight", Numeric, "Continuous", Format( "Best", 10 ) )
),
Lines To Read( 10 ));
Use Apostrophe as Quotation Mark
For data that are enclosed in apostrophes, this option treats apostrophes as quotation marks and omits them. For example, ’2010’ is imported as 2. This is a Boolean value. The default value is false.
This option is not recommended unless your data comes from a nonstandard source that places apostrophes around data fields rather than quotation marks.
Set Text Import Preferences
If you want to set preferences for importing text, it can be helpful to first see a list of all preferences. To do so, use the Show Preferences (All) function.
Then, copy and paste only the section you want into a Preferences function. For example, to specify import settings, write the following expression:
Preferences(Import Settings(
End Of Field( Tab, Spaces, Comma )
)
);
Import Data from a Microsoft Excel File
When you open a Microsoft Excel workbook in JMP, the file is converted to a data table. JMP supports .xls, .xlsm, and .xlsx formats. See Import Microsoft Excel Files in Using JMP for more information about Microsoft Excel support.
Excel Preferences
In the JMP preferences, settings in the General group can help determine how worksheets are imported:
Excel Open Method
Specifies how a Microsoft Excel file should be opened by default, when using a non-specific open statement.
Use Excel Wizard
Opens the Excel Import Wizard to import the file. This is the default setting.
Open All Sheets
Opens all worksheets in the Microsoft Excel file.
Select Individual Worksheets
Prompts users to select one or more worksheets when they open the file.
Use Excel Labels as Headings
Determines whether text in the first row of the worksheet is converted to column headings in the data table.
By default, JMP takes the best guess. If names have been defined for all cells in the first row, the text in those cells is converted to column heading. Otherwise, columns are named Column 1, Column 2, and so on.
To override a preference, include the corresponding argument described later in this section.
Note: See Create Excel Workbooks for information about exporting data tables to an Excel workbook.
Open() Function
Using the Open() function without additional arguments to open an Excel file has different behaviors depending on the context:
• If the Open() function is a direct part of the script, the Excel files open into data tables using your Excel preferences. The following example opens both worksheets into data tables without using the wizard:
Path = Convert File Path( "$SAMPLE_IMPORT_DATA/Team Results.xlsx", absolute );
dt = Open( Path );Note: To use the Excel Wizard, you must specify the Excel Wizard option in the argument as in Open( "$SAMPLE_IMPORT_DATA/Team Results.xlsx", "Excel Wizard" );.
• However, if the Open() function is part of a script that is run from clicking a button, the Preview window opens and requires the user to interact with it. Run the following example and click the button to see the Excel Import Wizard:
Path = Convert File Path( "$SAMPLE_IMPORT_DATA/Team Results.xlsx", absolute );
New Window( "button", Button Box( "Open", dt = Open( Path ) ) );
• To prevent the button script from opening the Preview window and importing the Excel file directly, provide additional arguments to the Open() function. Run the example and click the button. Both worksheets are opened into data tables without using the Excel Import Wizard.
Path = Convert File Path( "$SAMPLE_IMPORT_DATA/Team Results.xlsx", absolute );
New Window( "button", Button Box( "Open", dt = Open( Path, Use for all sheets(1) ) ) );
Alternatively, you can set the Excel Open Method preference to open all sheets, as follows:
Preference( Excel Open Method( "Open All Sheets" ) );
Path = Convert File Path( "$SAMPLE_IMPORT_DATA/Team Results.xlsx", absolute );
New Window( "button", Button Box( "Open", dt = Open( Path ) ) );
Open a Workbook in the Excel Import Wizard
The Excel Import Wizard shows a preview of the data and lets you modify the settings before importing the data. Specify "Excel Wizard" as the argument.
dt = Open( "$SAMPLE_IMPORT_DATA/Team Results.xlsx", "Excel Wizard" );
You can also customize settings such as the number of rows in the column headers.
dt = Open("$SAMPLE_IMPORT_DATA/Bigclass.xls", "Excel Wizard"
Worksheets( "Bigclass" ), Use for all sheets( 1 ), Concatenate Worksheets( 0 ), Create Concatenation Column( 0 ),Worksheet Settings(
1, Has Column Headers( 1 ), Number of Rows in Headers( 1 ), Headers Start on Row( 1 ), Data Starts on Row( 2 ), Data Starts on Column( 1 ), Data Ends on Row( 0 ), Data Ends on Column( 0 ), Replicated Spanned Rows( 1 ), Replicated Spanned Headers( 0 ), Suppress Hidden Rows( 1 ), Suppress Hidden Columns( 1 ), Suppress Empty Columns( 1 ), Treat as Hierarchy( 0 ), Multiple Series Stack( 0 ), Import Cell Colors( 0 ), Limit Column Detect( 0 ), Column Separator String( "-" ))
);
When you click a custom button to open a workbook, the Excel Open Method preference applies. To force the worksheet to open directly, specify the Excel Open Method in your script:
Preference( Excel Open Method( "Open All Sheets" ) );
Import Specific Worksheets
Suppose that you want to import data from specific worksheets in your workbook. Specify those worksheets using the Worksheets argument. In the following example, the worksheet named small is imported into JMP.
Open( "C:\My Data\cars.xlsx", Worksheets( "small" ) );
Or specify the number of the worksheet, the third worksheet in the following example:
Open( "C:\My Data\cars.xlsx", Worksheets( "3" ) );
Import multiple or all worksheets by including the worksheet names in a list:
Open( "C:\My Data\cars.xlsx", Worksheets( {"small", "medium", "large"} ) );Highlight a Specific Worksheet
The worksheets in a workbook appear in the upper right corner of the Excel Import Wizard. You can highlight a specific worksheet using the following expression:
Open(
"C:/Data/MultipleWorksheets.xlsx", Excel Wizard,
Worksheets( "Planets" ) // highlighted worksheet
);
Import XML and JSON Files
The XML Import Wizard imports two types of nested text data: XML and JSON files. Both kinds of files contain structured text that can be nested to represent hierarchical relationships. This wizard helps you pick out the elements of the hierarchy that hold values and elements that determine rows to build a data table.
A useful way to imagine a nested text file: the document is a book of short stories. Some of the short stories might have chapters, others only have paragraphs. Chapters have paragraphs. Paragraphs have sentences. Here’s an example of the full tree for such a book. This content is also available in the JMP Samples/Import Data directory as Book.xml.
<book>
<story name="car poll">
<wheels>4</wheels>
<para><name>chev</name></para>
<para><name>ford</name></para>
<para><name>volk</name></para>
</story>
<story name="big class">
<para><name>ralph</name><height>6</height></para>
<para><name>billy</name><height>5</height></para>
</story>
<story name="cheese" location="NC">
<chapter name="american">
<para>1<price>2.00</price><quantity>2</quantity></para>
<para>2<price>2.10</price><quantity>4</quantity></para>
<para>3<price>2.20</price><quantity>3</quantity></para>
</chapter>
<chapter name="swiss">
<para>1<price>3.00</price><quantity>3</quantity></para>
<para>2<price>3.10</price><quantity>2</quantity></para>
</chapter>
</story>
</book>
This XML document (the book) contains three short stories; each short story is a data table, all different. This particular XML file uses paragraphs to represent rows in a table in all of the tables. That is not required, nor are any of the names special. If you wanted to import the cheese table, which is slightly more complicated than the other two, you'd probably want a variety column, containing “american” or “swiss” for each row. You would also want price and quantity columns. And you might want a column that doesn't have a clearly defined name for the 1, 2, 3, 1, 2 values of <para>. You’d expect five rows. Finally, you might want a table variable or a column for the location NC value.
The following example shows how to import the preceding data into a data table.
Open( "$SAMPLE_IMPORT_DATA/Book.xml",XML Settings(
Row( "/book/story/chapter/para" ),
// create a row for each value in <para>Col(
"/book/story/@location", // create a column for the location attribute Column Name( "location" ), // rename the column Fill( "Use Forever" ), // fill an empty cell with the preceding valueType( "Character" ), // data type
Format( "best" ) // column format
),
Col(
"/book/story/chapter/@name", Column Name( "variety" ), Fill( "Use Once" ), Type( "Character" ), Format( "best" )),
Col(
"/book/story/chapter/para", Column Name( "interesting" ), Fill( "Use Once" ), Type( "Numeric" ), Format( "best" )),
Col(
"/book/story/chapter/para/price", Column Name( "price" ), Fill( "Use Once" ), Type( "Character" ), Format( "best" )),
Col(
"/book/story/chapter/para/quantity", Column Name( "quantity" ), Fill( "Use Once" ), Type( "Character" ), Format( "best" ))
),
XML Wizard( 0 ) /* omit or change to 1 to preview the data
) in the XML Import Wizard */Import from and Export to Google Sheets
A Google Sheet is a spreadsheet (which consists of sheets, like tabs) that is saved in your Google account. This enables you to continue to edit the spreadsheet and to share it with others.
To write a script to import data from a Google spreadsheet, log in to your Google account and get the URL for the spreadsheet. Also notice how the data is structured. For example, you must know which row the data begin on if there are column headers.
When you run the script, Google prompts you to allow JMP to access your account. Google also provides you with an authorization code. Display the script and paste the code into the Authorization Code box. Then the script continues to run.
To import data from a Google spreadsheet
dt = Google Sheet Import(
Email( "yourgoogleaccount@gmail.com" ), // modify the email address
// modify the sheet URL
Spreadsheet( "https://docs.google.com/spreadsheets/d/1J01M4ScGsAHb-bCUa0i575WWvQjXciQIVN0wVTrXDSe/edit#gid=2303744702" ),
Sheets( "May","June" ), // specify the sheet name(s)
Sheet Settings( // specify the structure of the data
Has Column Headers( 1 ),
Headers Start on Row ( 1 ),
Data Starts on Row( 2 ),
Cell Range( "" ),
Import Cell Colors( 1 ),
Suppress Empty Columns( 1 )
)
);
Note: See About Importing Google Sheets in Using JMP for more information about security, country restrictions, and more.
To export a JMP data table to a Google spreadsheet
Export a JMP data table to a new spreadsheet in Google Sheets by following this example:
email = "yourgoogleaccount@gmail.com"; // modify the Google account
dt = Open( "$SAMPLE_DATA/Big Class.jmp" );
Google Sheet Export(
dt,
Email( email ),
New Spreadsheet( "JSL Example" ), // specify the name of the spreadsheet
Sheet Name( "Example 1" ) // specify the sheet name
);
“1” is returned in the log when the export is successful.
Export a JMP data table to an existing spreadsheet in Google Sheets by following this example. You’ll need the URL of the existing spreadsheet.
id = "https://docs.google.com/spreadsheets/d/1J01M4ScGsAHb-bCUa0i575WWvQjXciQIVN0wVTrXDSe/edit#gid=2303744702"; // modify the URL
email = "yourgoogleaccount@gmail.com"; // modify the Google account
dt = Open( "$SAMPLE_DATA/Big Class.jmp" );
Google Sheet Export(
dt,
Email( email ),
Spreadsheet( id ),
Sheet Name( "Example 1" )
);
“1” is returned in the log when the export is successful.
Note: See About Exporting Google Sheets in Using JMP for more information about security, country restrictions, and more.
Import SAS Data Sets
Open a SAS file as a data table without connecting to a SAS server.
sasxpt = Open( "$SAMPLE_IMPORT_DATA/carpoll.xpt" );
To convert the labels to column headings, include the Use Labels for Var Names argument.
sasdbf = Open( "$SAMPLE_IMPORT_DATA/Bigclass.sas7bdat", Use Labels for Var Names( 1 ));
.xpt and .stx file formats are also supported.
On Windows, you can also open SAS data sets from a SAS server. See Connect to a SAS Metadata Server in the Extending JMP section.
Import Web Pages and Remote Files
You can import data from websites or from other computers. The data might be a JMP data table, a table defined in a web page, or another file type that JMP supports.
Open or Import Data from a Website
In the Open() command, specify the quoted URL to open a file from a website. You can open JMP data tables or other supported file types this way.
Open( "http://company1.com/Repairs.jmp" );
Open( "http://company1.com/My Data.txt", text); // specify text on macOS
Import a Web Page
A web page can include data in tabular format. Import the table as a JMP data table as follows:
Open( "http://company1.com", HTML Table( n ) );n identifies which table you want to import. For example, to import the fourth table on the page, specify HTML Table(4). If you omit the value, only the first table on the page is imported.
JMP attempts to preserve the table header defined in a <th> HTML tag. The table header is converted to column headings in the data table. If the <th> tag is wrong or missing, use ColumnNames(n) to specify the nth row. By default, DataStarts(n) will be the next row, or you can specify the DataStarts row.
Import Images from a Web Page
You can import images on the web into a data table, using the Expression data type. The following example creates a new data table and adds two images to it.
dt = New Table( "test", New Column( "Image", Expression ) );
dt << Add Rows( 1 );
dt:Image = New Image( Open( "http://www.jmp.com/support/help/15/images/MosaicPlot.png" ) );
dt << Add Rows( 1 );
dt:Image = New Image( Open( "http://www.jmp.com/support/help/15/images/tTest_NoLoc.png" ) );
Import Images from a Directory
You can use Multiple File Import() and an Event Handler script to create a data table of thumbnail images that link to a directory of full-size pictures. This example sets the cell height so that it fits the height of the tallest thumbnail.
Note: Typically, the Multiple File Import option is for importing multiple text files. However, this example shows how to use the option to import images.
path = "$SAMPLE_IMAGES/"; // images are in this directory
{dtx} = Multiple File Import( <<Set Folder( path ),<<Set Name Filter( "*.jpg; " ),
<<Set Name Enable( 1 ), /* enable the ability to filter by name,
in this example, files with the .jpg extension */
<<Set Add File Name Column( 1 ), // must be included but can be hidden
<<Set Add File Size Column( 1 ) // for Show Sizes at end
) << Import Data;/* FileName is the column that contains the image file name.
The column is required for the image links to work, but you don’t need
to see it. */
dtx:FileName << Hide;maxheight = 0;For Each Row( // recreate each image to minimize size of data table
x = Eval( dtx:Picture );x << Scale( .1 ); // scale the image by 10%
m = x << Get Pixels; // compress the image by recreating it
dtx:Picture = New Image( m );maxheight = Max( maxheight, (dtx:Picture[] << Get Size)[2] );
// width x height is returned, [2] gets the height
);
Eval( /* insert the value in the path variable into the Click handler. The path variable won’t be available later, but the path value is needed to concatenate with the file name column’s value to build a link to the image on the computer. */
Eval Expr( dtx:picture << Set Property( "Event Handler",Event Handler( // Event Handler column property
Click( JSL Quote( Function( {thisTable, thisColumn, iRow},
// insert links to imagesOpen( Expr( path )||Char( thisTable:FileName[ iRow ] ) ); ); ) ),
Tip( JSL Quote( Function( {thisTable, thisColumn, iRow}, "Open " || Char( thisTable:FileName[ iRow ] ) || " in your viewer."; ); ) ),
// color of the link -- blue
Color( JSL Quote( Function( {thisTable, thisColumn, iRow}, 5; );) )
) )
)
);
// add two pixels to the maximum height
dtx << Set Cell Height( maxheight + 2 );
/* save the file to show that the data table is much smaller than the
original file */
dtx << Save( "$TEMP/Sample Images.jmp" );
Show( File Size( "$TEMP/Sample Images.jmp" ), Col Sum( dtx:FileSize ) );
Import a File from a Shared Computer
JMP can import files stored on a shared computer, such as another computer or a network drive. The following example shows how to open a file from Windows:
Open( "\\Data\Repairs.jmp" ); // UNC name
Open( "z:/Data/Repairs.jmp" ); // mapped letter drive
Open( "Repairs.jmp" ); // relative path in which the script is in the same directory as the file that you are importing
macOS doesn’t have a concept like UNC naming or drive letters. Instead, you need to mount the volume through the user interface. It is possible to do it from a script, but you would need to have connected interactively at least once and stored the password in your keychain.
Here is an example that connects to a remote volume from either macOS or Windows:
mount = Function( {server}, {Default Local},If( Host is( Mac ),
Run Program(
Executable( "/usr/bin/osascript" ),
// replace ^server^ with your server name throughout the script
Options( {"-e", Eval Insert( "mount volume \!"smb://^server^\!"" )} ),Read Function( "text" )
);
server = Concat Items( Remove( Words( server, "/" ), 1 ), "/" );
Eval Insert( "/Volumes/^server^" );
,
Eval Insert( "\!\\!\^server^" )
)
);
users = mount( "data.company.com/Users" );
Files In Directory( Eval Insert( "^users^/Smith" ) );
Import JSON Data
JSON (JavaScript Object Notation) is a data interchange format that is based on JavaScript. It shares many of the same principles as languages based on C and is easy to read and write. Because of these characteristics, JSON is highly portable and can be imported into JMP.
JSON | JSL |
|---|---|
array | list (sequence of values) |
object | associative array (set of named values) |
number | number |
string | string |
true | 1.0 |
false | 0.0 |
null | . (missing value) |
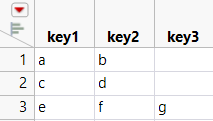
JSON consists of name-value pairs in an associative array. For example, here is JSON code that shows name-value pairs:
"[ { \!"key1\!": \!"a\!", \!"key2\!": \!"b\!"}, {\!"key1\!": \!"c\!", \!"key2\!": \!"d\!" }, {\!"key2\!": \!"f\!", \!"key1\!":\!"e\!", \!"key3\!": \!"g\!"}]";Each list is imported as a column in the data table. “key1” is the name of the first column. The first value in the column is “a”. The second value is “c”, and the third value is “e”.
Use JSON To Data Table() to convert the JSON into a data table.
js = "[ { \!"key1\!": \!"a\!", \!"key2\!": \!"b\!"}, {\!"key1\!": \!"c\!", \!"key2\!": \!"d\!" }, {\!"key2\!": \!"f\!", \!"key1\!":\!"e\!", \!"key3\!": \!"g\!"}]";d = JSON To Data Table( js ); // convert JSON to a data table
d << New Data View; // make a view of the data table
Figure 9.6 Imported JSON Data
You can also use JSON To List() to convert a string containing JSON into a list.
list = JSON To List( "[ { \!"name\!": \!"KATIE\!", \!"age\!": 12, \!"sex\!": \!"F\!", \!"height\!": 59, \!"weight\!": 95 }, { \!"name\!": \!"LOUISE\!", \!"age\!": 12, \!"sex\!": \!"F\!", \!"height\!": 61, \!"weight\!": 123 }, { \!"name\!": \!"JANE\!", \!"age\!": 12, \!"sex\!": \!"F\!", \!"height\!": 55, \!"weight\!": 74 } ]");
Show( list );list = {{{"name", "KATIE"}, {"age", 12}, {"sex", "F"}, {"height", 59}, {"weight", 95}}, ...}}};
Exporting JSL to JSON
As JSON Expr() converts an associative array to a JSON string. You can then export the data into a JSON document.
list_of_associative_arrays = {["key1" => "a", "key2" => "b"], ["key1" => "c","key2" => "d"], ["key2" => "f", "key1" => "e", "key3" => "g"]};
jx = As JSON Expr( list_of_associative_arrays );"[{\!"key1\!":\!"a\!",\!"key2\!":\!"b\!"}..."[{\!"key1\!":\!"a\!",\!"key2\!":
\!"b\!"}
Note: To import the data table as invisible, include the argument Invisible(1) in JSON To Data Table() and omit New Data View.
Import HDF5 Files
Hierarchical Data Format, Version 5 (HDF5) is a portable file format for storing data. An HDF5 file consists of groups and datasets. When you import the file, JMP opens a group to present the names of the inner datasets.
JMP handles only tables with numeric (integer, float, double) and string types, and compound files with three or fewer dimensions that contain only simple types.
You can import up to 1,000,000 columns and an unbounded number of rows.
The syntax is as follows:
Open( "filename.h5", {"list_of", "dataset_names"});Errors are written to the log when invalid data set names are passed.
Import ESRI Shapefiles
An ESRI shapefile is a geospatial vector data format used to create maps. JMP imports shapefiles as data tables. A .shp shapefile consists of coordinates for each shape. A .dbf shapefile includes values that refer to regions. To create maps in JMP, you modify the structure of the data and save the files with specific suffixes.
The following example imports a .shp file and saves it with the -XY suffix.
dt = Open( "$SAMPLE_IMPORT_DATA/Parishes.shp",
:X << Format( "Longitude DDD", 14, 4 );
:Y << Format( "Latitude DDD", 14, 4 ) );
dt << Save( "c:/Parishes-XY.jmp" );
Save the .dbf file with the -Name suffix.
dt = Open( "$SAMPLE_IMPORT_DATA/Parishes.dbf" );
dt << Save( "c:/Parishes-Name.jmp" );
Restructuring the data requires several steps, including adding a Map Role column property to names in the -Name.jmp file. See Map Role in Essential Graphing.
Import a Database
Open Database() opens a database using Open Database Connectivity (ODBC) and extracts data into a JMP data table. See the Database Access in the Extending JMP section.
JMP also converts DataBase Files (.dbf) files to data table format.
sasdbf = Open( "$SAMPLE_IMPORT_DATA/Bigclass.dbf",
Use Labels for Var Names( 1 ));