データベーステーブルを選択(そして必要に応じて結合)したら、[クエリーの作成]をクリックしてクエリービルダーウィンドウを開きます。含める列を選択し、標本抽出の基準やフィルタを指定して、クエリーを作成します。また、クエリーを保存し、後で編集、実行することもできます。
「選択可能な列」リストにデータベーステーブルの列がすべて一覧されます。t1やt2といった接頭部(エイリアスともいう)が、各列を対応するデータベーステーブルに関連付けます。
クエリービルダーの手順を省き、すべてのデータを読み込む場合は、[すぐに読み込む]をクリックします。
メモ: [テーブル]メニューの[JMPクエリービルダー]にも同じオプションが多くありますが、JMPデータテーブルを照会および結合できるという点で異なります。詳細については、「データの再構成」章の「[JMPクエリービルダー]を使用したデータテーブルの照会と結合」(311ページ)を参照してください。
|
1.
|
|
2.
|
|
3.
|
|
4.
|
[クエリーの作成]をクリックすると、クエリービルダーウィンドウが開きます。
|
|
5.
|
|
6.
|
[含める列]タブで[追加]をクリックします。
|
図3.33 選択されている列
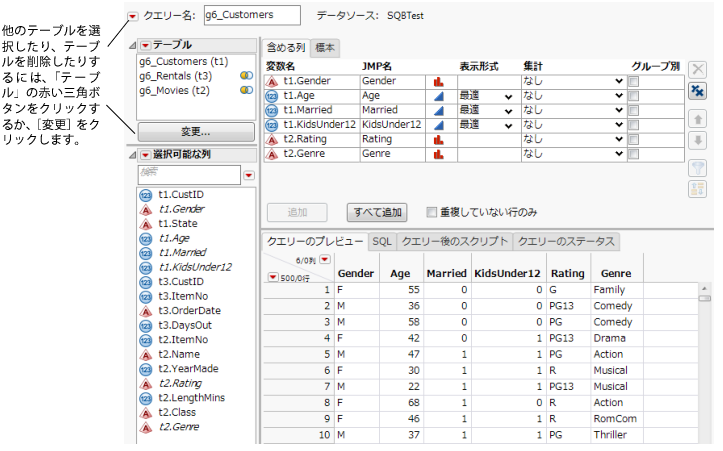
|
7.
|
列の下にある[SQL]タブを選択すると、クエリーのSQLステートメントが確認できます。このコードは、クエリーの実行後、データテーブルプロパティとして保存されます。
|
|
8.
|
右下角の[保存]をクリックします。
|
作業内容は、「g6_Customers.jmpquery」として保存されます。後でこのファイルを開けば、現在の時点に戻ったり、クエリーを実行したりできます。
|
9.
|
[クエリーの実行]をクリックし、データを読み込みます。
|
|
•
|
エイリアスを変更するには、「クエリーのテーブルを選択」ウィンドウでテーブルを右クリックし、[エイリアスの変更]を選択します。エイリアスには大文字と小文字の区別がありません。
|
|
•
|
[クエリービルダー]の環境設定で、「ODBC」の[可能な限りクエリーをバックグラウンドで実行]をオフにしない限り、クエリーはバックグラウンドで実行されます。ODBCクエリーの進行状況は、[表示]>[実行中のクエリー]で確認することもできます。
|
|
•
|
プレビューのロードに時間がかかり過ぎる場合は、[プレビューを自動的に更新]をオフにします。データのビューを更新するには、[クエリーのプレビュー]タブの下にある[更新]をクリックします。大規模なデータベースを使用することが多い場合は、「クエリービルダー」の環境設定にあるプレビューオプションの変更を検討してください。また、プレビュー可能な行の最大数を制限することを検討してください。JMPの[クエリービルダー]の環境設定で、[プレビュー表示する最大行数]の値を変更します。
|
|
•
|
データベースの重複する行を省略するには、[含める列]タブで[重複していない行のみ]を選択します。
|
JMP 13で追加された機能をクエリーに追加した場合、そのクエリーはJMP 12では読み込めなくなります。JMP 13を使用しているが、JMP 12でも実行できるクエリーを作成したい場合は、[クエリービルダー]の環境設定で[デフォルトでJMP 12とのクエリーの互換性を維持する]を選択します。このオプションを選択すると、互換性の問題を生じる機能がクエリービルダーで非表示になります。
既存の列から新しい列を作成できます。たとえば、2つの列の平均を計算し、その平均を新しい列に保存できます。この場合、日時の値には間違った形式が用いられることがあります。「選択可能な列」の赤い三角ボタンのメニューで[計算列の追加]を選択し、計算式エディタで新しい列を作成します。
|
1.
|
|
2.
|
|
3.
|
[クエリーの作成]をクリックすると、クエリービルダーウィンドウが開きます。
|
|
4.
|
「選択可能な列」の赤い三角ボタンをクリックし、表示されるメニューで[計算列の追加]を選択します。
|
すると、計算列ウィンドウが表示されます(計算式エディタを伴う計算列ウィンドウ)。このウィンドウにはJMPの計算式エディタが含まれています。
図3.34 計算式エディタを伴う計算列ウィンドウ
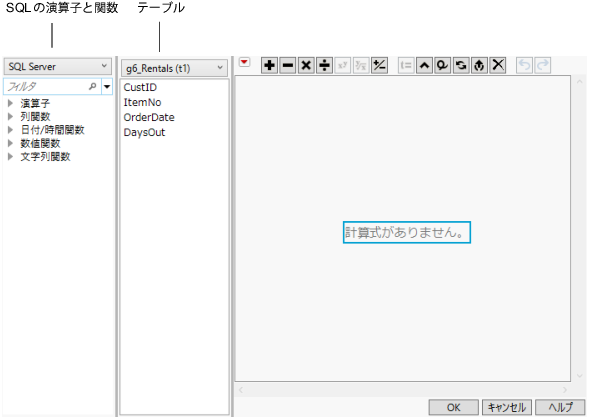
|
–
|
計算式エディタの左側のリストには演算子と関数があります(計算式エディタを伴う計算列ウィンドウ)。データベースに基づいてサーバーのタイプを変更しなければならない場合があります。
|
|
–
|
「演算子」のリストにConcatenate(||)演算子は含まれていません。手動で計算エディタボックスに入力する必要があります。
|
|
5.
|
 のボタンをクリックします。
のボタンをクリックします。
図3.35 計算列

図3.36 計算式の最初の部分
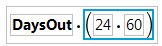
 のボタンをクリックします。
のボタンをクリックします。|
8.
|
図3.37 次に表示される計算式
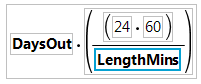
|
9.
|
[OK]をクリックします。
|
|
10.
|
この列を右クリックし、[列名の変更]を選択します。
|
|
11.
|
「見ることのできる最大回数」と入力し、[OK]をクリックします。
|
|
12.
|
|
13.
|
「t2.Name」を選択し、[追加]をクリックします。
|
|
1.
|
|
2.
|
|
3.
|
[クエリーの作成]をクリックすると、クエリービルダーウィンドウが開きます。
|
|
4.
|
|
5.
|
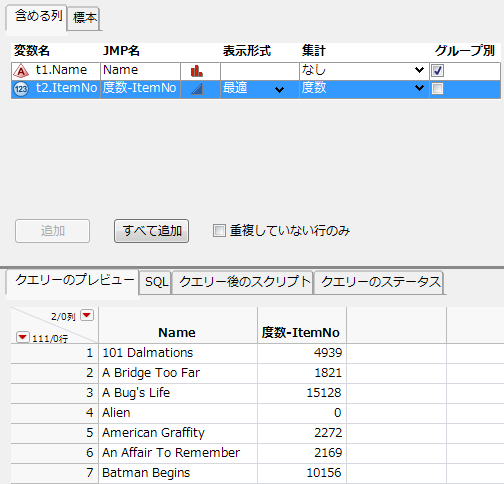
「t2.ItemNo」を選択し、「集計」リストから[度数]を選択します。
|
図3.38 グループ化した列
|
6.
|
[クエリーの実行]をクリックし、データを読み込みます。
|
|
7.
|
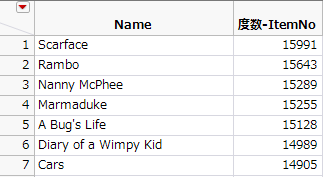
図3.39 「度数-ItemNo」列を並べ替えたところ
|
•
|
行のグループ化を解除するには、列の「集計」リストで[なし]を選択します。
|
|
1.
|
|
2.
|
|
3.
|
[クエリーの作成]をクリックすると、クエリービルダーウィンドウが開きます。
|
|
4.
|
[含める列]タブで[すべて追加]ボタンをクリックします。
|
|
5.
|
[標本]タブをクリックし、[この結果セットから標本抽出]を選択します。
|
|
6.
|
[行数(ランダムに抽出)]を選択し、「5000」と入力します。
|
|
7.
|
[クエリーの実行]をクリックし、データを読み込みます。
|
|
•
|
フィルタを使い、値のサブセットをデータテーブルに読み込むこともできます。クエリーにJMP 12との互換性がある場合は、一部のフィルタが使用できなくなります。詳細については、第 “JMP 12との互換性の維持”を参照してください。
Age > 14は、14を超える年齢にマッチします。
12 ≤ Age ≤ 17は、12~17の年齢にマッチします。
[NULLまたはnot NULLのいずれか]は欠測値と非欠測値にマッチします。
( ( ( t2.Gender IN ( 'F' ) ) AND ( (t2.Age >= 20) AND (t2.Age <= 50) ) ) )
指定した値を含む、または含まない文字列にマッチします。Contains Comedy OR RomanceはComedyとRomanceにマッチします。
Genre Like %comは、“RomCom”など、“com”前に任意の数の文字がある値にマッチします。 “Comedy”にもマッチするようにするには、%com%またはContains comを使用します。
指定した列の値にマッチします。テーブルを選択した後、列を選択します。[一致しないものを選択]オプションを使用すると、選択した行を除くすべての行が得られます。例については、第 “既存のデータテーブルから一致するデータを読み込む”を参照してください。
|
1.
|
|
2.
|
|
3.
|
|
4.
|
[クエリーの作成]をクリックし、クエリービルダーウィンドウを開きます。
|
|
5.
|
|
6.
|
 をクリックします。
をクリックします。|
7.
|
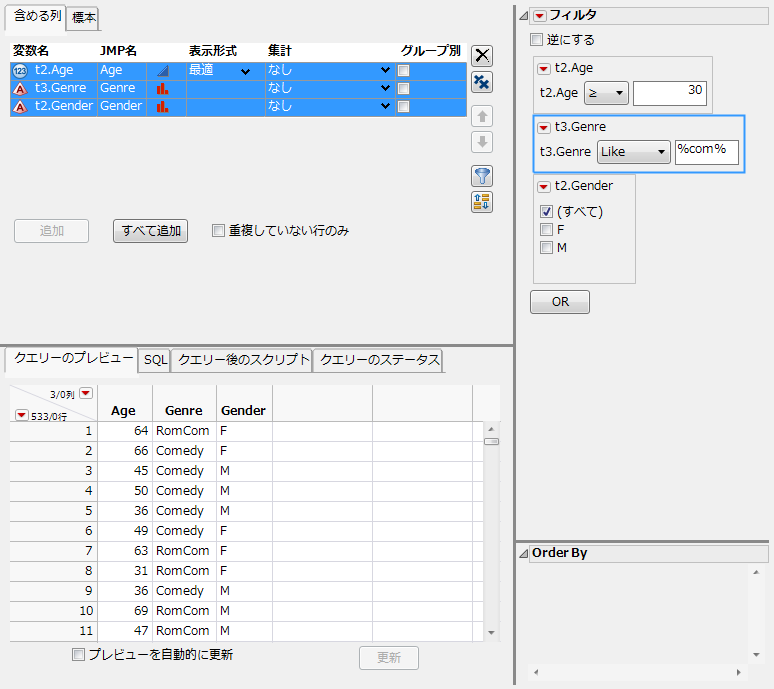
「t2.Age」のフィルタを「≥ 30」に設定します。
|
|
8.
|
「com」の前後のワイルドカード(%)は、任意の数の文字に一致します。[クエリーのプレビュー]タブに、「RomCom」(ロマンティックコメディ)と「Comedy」(コメディ)の2つのジャンルの映画が表示されています(フィルタの選択)。
図3.40 フィルタの選択
|
9.
|
「フィルタ」の赤い三角ボタンのメニューで、[実行時にすべての確認メッセージを表示]を選択します。
|
|
10.
|
[クエリーの実行]をクリックします。
|
|
11.
|
「クエリーの確認」ウィンドウで[OK]をクリックすると、選択済みのフィルタを適用してデータが読み込まれます。
|
|
–
|
[クエリービルダー]の環境設定にある[サイズが判断できないテーブルのカテゴリの水準を取得する]はデフォルトで選択されているため、JMPは自動的に水準を取得しようとします。このオプションの選択を解除すると、[クエリービルダー]の環境設定の「カテゴリカル列の代替のフィルタタイプ」で指定されている[含む]のフィルタが使用されます。
|
|
–
|
カテゴリカルな列に百万を超える行がある場合、JMPはそのフィルタ列から一意の水準値を取得しません。[クエリービルダー]の環境設定の「カテゴリの水準を自動的に取得するテーブルの最大行数」に指定できる値は、最小値である-1(制限なし)から最大値である10億までです。
|
|
•
|
[クエリービルダー]の環境設定で[デフォルトでJMP 12とのクエリーの互換性を維持する]が選択されていない限り、カテゴリカルな列のデフォルトのフィルタはリストボックスです。
|
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Air Traffic.jmp」を開きます。
|
|
2.
|
|
3.
|
|
4.
|
[クエリーの作成]をクリックし、クエリービルダーウィンドウを開きます。
|
|
5.
|
[含める列]タブで[すべて追加]をクリックします。
|
|
6.
|
|
7.
|
|
8.
|
「値を比較するテーブル」の下で「Air Traffic」を選択します。
|
|
9.
|
「機体番号」列を選択し、リストから「すべての行 (38,118)」を選択します。
|
|
10.
|
[クエリーの実行]をクリックし、データを読み込みます。
|
読み込まれたデータテーブルには、「機体番号」列にある機体番号のデータのみが含まれています。
|
2.
|
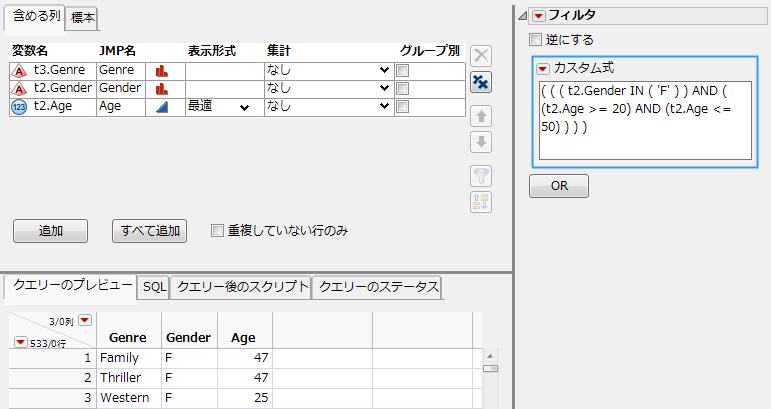
「フィルタ」の赤い三角ボタンのメニューから[カスタム式の追加]を選択します。
|
( ( ( t2.Gender IN ( 'F' ) ) AND ( (t2.Age >= 20) AND (t2.Age <= 50) ) ) )
図3.41 カスタムのフィルタ式を書く
|
1.
|
|
2.
|
|
3.
|
[クエリーの作成]をクリックすると、クエリービルダーウィンドウが開きます。
|
|
4.
|
[含める列]タブで[すべて追加]をクリックします。
|
|
5.
|
 をクリックします。
をクリックします。
図3.42 「Order By」列の選択
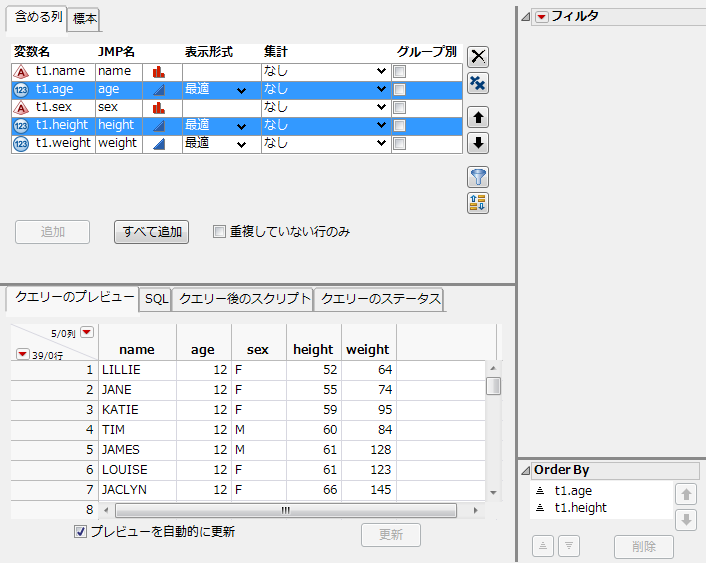
|
6.
|
 をクリックします。
をクリックします。「height」列が、高い順に並べ替えられます。
|
7.
|
 をクリックします。
をクリックします。
図3.43 列を並べ替えた結果
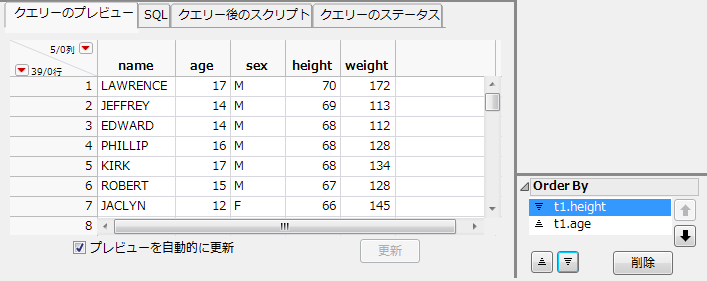
[クエリーのステータス]タブで、バックグラウンドで実行されているクエリーのステータスを確認できます。クエリー名、SQLステートメント、処理されたレコードの数が表示されます。いつでもクエリーを停止し、処理されたレコードのみを確認することができます。他のJMPウィンドウからバックグラウンドクエリーを確認するには、[表示]>[実行中のクエリー]を選択します。「クエリービルダー」の環境設定で[可能な限りクエリーをバックグラウンドで実行]をオフにした場合、ステータスの詳細は表示されません。
Distribution( Column( :age, :gender ) );