効果に対する検定を行うときに比較される統計量です。第 “最小2乗平均表”を参照してください。
名義/順序尺度の主効果/交互作用に対して、最小2乗平均をプロットします。効果が交互作用の場合、このオプションを選択すると、最初に「最小2乗平均プロットのオプション」ウィンドウが開きます。第 “最小2乗平均プロット”を参照してください。
メモ: この検定のp値や信頼区間は、すべての比較に対してではなく、個々の1つ1つの比較に対して計算されたものです。一般的に、すべての比較における第1種の誤りの確率は、個々の比較における第1種の誤りの確率よりも大きくなります。
Tukey-KramerのHSD(Honestly Significant Difference)検定(Tukey 1953, Kramer, 1956)を使って、最小2乗平均のペアごとの比較に関する検定および信頼区間を計算します。第 “Studentのt検定とTukeyのHSD検定”を参照してください。
メモ: この検定のp値や信頼区間は、すべてのペアの比較をまとめて考慮して調整されたものです。この検定は、標本サイズが等しい場合は正確で、標本サイズが異なる場合は保守的になります(Hayter, 1984)。
最小2乗平均は、指定のモデルで他の効果を中立的な値に固定したときの、名義/順序尺度である効果の各水準における予測値です。連続尺度の説明変数では、標本平均が「中立的な値」として使用されます。名義尺度の効果では、その効果の係数を平均した値(つまり、ゼロ)が「中立的な値」として使用されます。順序尺度の効果では、最初の水準が「中立的な値」として使われます。
最小2乗平均は、調整済み平均または調整平均と呼ばれることもあります。モデルに複数の効果がある場合、最小2乗平均は単なる平均とは違う値になります。実際の場面では、最小2乗平均の値は、標本平均よりも互いに近くなるのが普通です。これは、最小2乗平均が「中立的な値」に基づいた予測値であるためです。
最小2乗平均は他の効果を特定の値に固定したときの予測値なので、それらを比較し、検定することができます。JMPでの各効果に対する検定は、最小2乗平均に対する検定になっています。最小2乗平均の詳細については、付録「統計的詳細」の「名義尺度の因子における最小2乗平均」(488ページ)および「順序尺度の因子における最小2乗平均」(498ページ)を参照してください。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Big Class.jmp」を開きます。
|
|
2.
|
[分析]>[モデルのあてはめ]を選択します。
|
|
3.
|
「体重(ポンド)」を選択し、[Y]をクリックします。
|
|
4.
|
|
5.
|
「強調点」のリストから[要因のスクリーニング]を選択します。
|
|
6.
|
[実行]をクリックします。
|
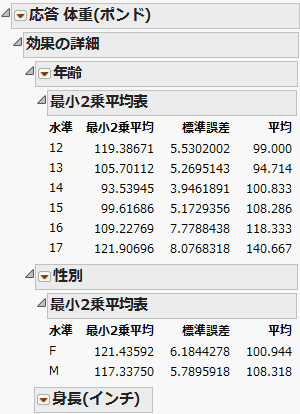
「効果の詳細」レポートには、3つの効果それぞれのレポートが表示されます(最小2乗平均表)。「年齢」と「性別」には最小2乗平均表が表示されていますが、連続尺度の効果である「身長(インチ)」には表示されていません。最小2乗平均が標本平均とどのように異なるかに注目してください。
図3.10 最小2乗平均表
[最小2乗平均プロット]のオプションでは、名義/順序尺度の主効果/交互作用に対して、[最小2乗平均プロット]を作成します。効果が交互作用の場合、このオプションを選択すると、最初に「最小2乗平均プロットのオプション」ウィンドウを呼び出されます。第 “最小2乗平均プロットのオプション”を参照してください。
図3.11 「最小2乗平均プロットのオプション」ウィンドウ
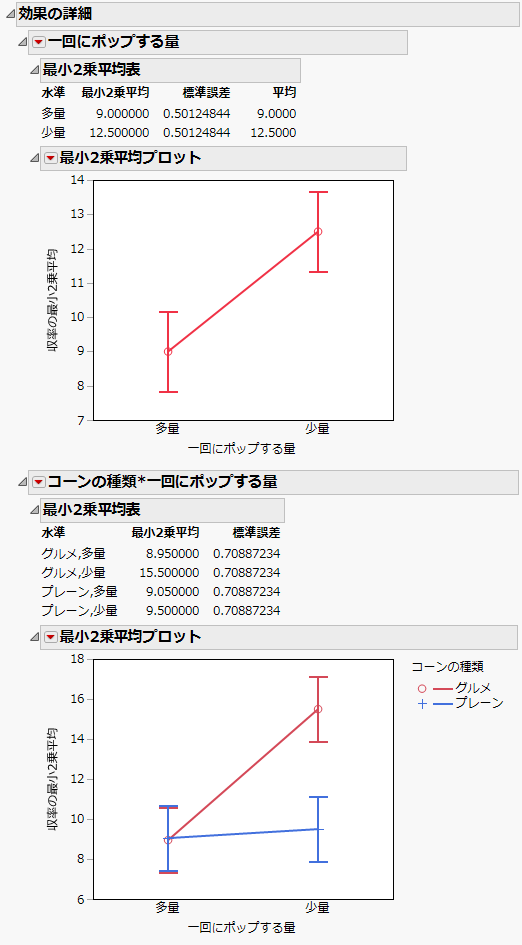
図3.12 2因子間交互作用の最小2乗平均表およびプロット
2因子間交互作用の最小2乗平均表およびプロットのレポートを作成するには、次の手順に従います。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Popcorn.jmp」を開きます。
|
|
2.
|
[分析]>[モデルのあてはめ]を選択します。
|
|
3.
|
「収率」を選択し、[Y]をクリックします。
|
|
4.
|
|
5.
|
[実行]をクリックします。
|
|
7.
|
[一回にポップする量]の赤い三角メニューで、[最小2乗平均プロット]を選択します。
|
|
8.
|
[コーンの種類*一回にポップする量]の赤い三角メニューで、[最小2乗平均プロット]を選択します。「最小2乗平均プロットのオプション」ウィンドウが表示されます。
|
|
10.
|
[重ね合わせ項を選択]から、[コーンの種類]を選択します。
|
|
11.
|
[OK]をクリックします。
|
|
13.
|
図3.13 因子を入れ替えた最小2乗平均プロット
因子を入れ替えた最小2乗平均プロットは、プロットする因子を入れ替えた後の「コーンの種類*一回にポップする量」のプロットです。2因子間交互作用の最小2乗平均表およびプロットのプロットと比較してください。これらのプロットは同じ情報を示していますが、プロットする因子を入れ替えています。
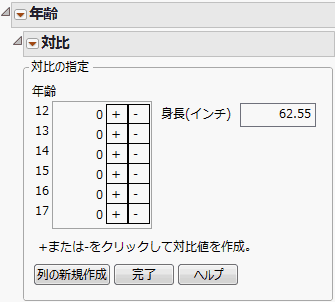
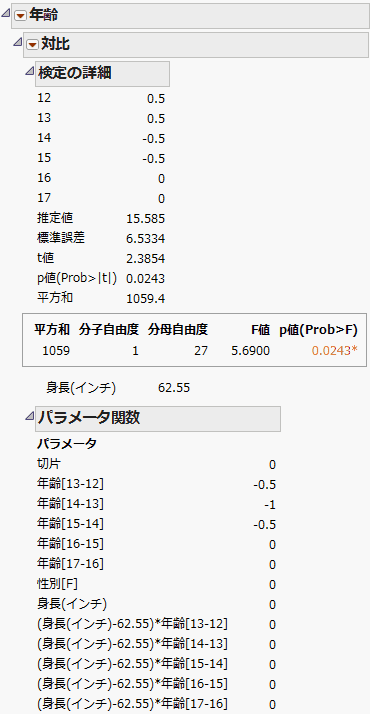
対比はパラメータ値の線形結合です。「対比の指定」パネルで、複数の対比を指定し、それらがすべてゼロかどうかを検定できます(「年齢」の対比を指定する)。
プラスボタンまたはマイナスボタンをクリックするたびに、合計が0、絶対値の合計が2になるように可能な限り正規化されます。線形結合を追加したい場合は、[列の新規作成]ボタンをクリックします。新しい列が表示され、ここで新しい対比を定義できます。完了したら、[完了]クリックします。「対比」レポートが表示されます(最小2乗平均の「対比」レポート)。全体の検定は、対比のすべての列に対する同時F検定です。
「対比」レポートには、同時F検定に関する次のような詳細が表示されます。
有意性検定のp値。
「パラメータ関数」レポート(最小2乗平均の「対比」レポート)には、指定した対比に対応した、モデルのパラメータに関する線形結合が表示されます。
次の手順に従い、「年齢」の対比を指定するのようなレポートを作成します。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Big Class.jmp」を開きます。
|
|
2.
|
[分析]>[モデルのあてはめ]を選択します。
|
|
3.
|
「体重(ポンド)」を選択し、[Y]をクリックします。
|
|
4.
|
|
5.
|
|
6.
|
[実行]をクリックします。
|
|
7.
|
「年齢」タイトルバーの赤い三角ボタンをクリックし、[最小2乗平均の対比]を選択します。
|
「年齢」の対比を指定するのような「対比の指定」パネルが表示されます。
図3.14 「年齢」の対比を指定する
|
10.
|
連続尺度の効果「身長(インチ)」の横にテキストボックスがあります。このデフォルト値は、該当する連続尺度の列の標本平均です。
|
|
11.
|
[完了]をクリックします。
|
最小2乗平均の「対比」レポートのような「対比」レポートが表示されます。対比の検定は、有意水準5%で統計的に有意です。身長が62.55インチである生徒においては、12歳と13歳の年齢グループの平均体重は、14歳と15歳の年齢グループの平均体重と、統計的に有意に異なると言えます。
図3.15 最小2乗平均の「対比」レポート
Studentのt検定と、TukeyのHSD(honestly significant difference)検定のオプションは、最小2乗平均をペアごとに比較します。
|
•
|
[最小2乗平均のStudentのt検定]オプションは、通常のt分布に基づき、検定結果が算出されています。各ペアに対する検定は、1つ1つの比較の有意水準に基づいています。複数の検定を行うと、全体において第1種の誤りを犯す確率は、1つあたりの検定の有意水準を上回ってしまいます。
|
|
•
|
「最小2乗平均のTukeyのHSD検定」レポートは、「Big Class.jmp」サンプルデータの「年齢」に対する「最小2 乗平均差のTukeyのHSD検定」レポートです (このレポートは、このサンプルデータに添付されている「モデルのあてはめ」スクリプトを実行した後、「年齢」の赤い三角ボタンのメニューから「最小2乗平均のTukeyのHSD検定」を選択すると表示できます)。このレポートは、デフォルトで[クロス集計レポート]と[文字の接続レポート]を表示します。
図3.16 「最小2乗平均のTukeyのHSD検定」レポート
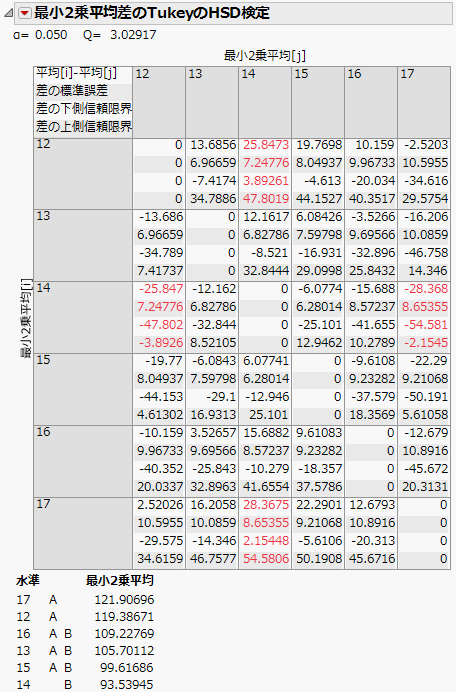
「最小2乗平均のTukeyのHSD検定」レポートでは、水準17、12、16、13、15が文字「A」でつながっています。この接続は、5%で有意ではないことを示しています。また、水準16、13、15、14は文字「B」でつながっており、これも5%で有意ではないことを示しています。しかし、年齢17と14、年齢12と14は、同じ文字でつながっていません。これは、これら2つの水準のペアでは、統計的に有意な差があることを示しています。
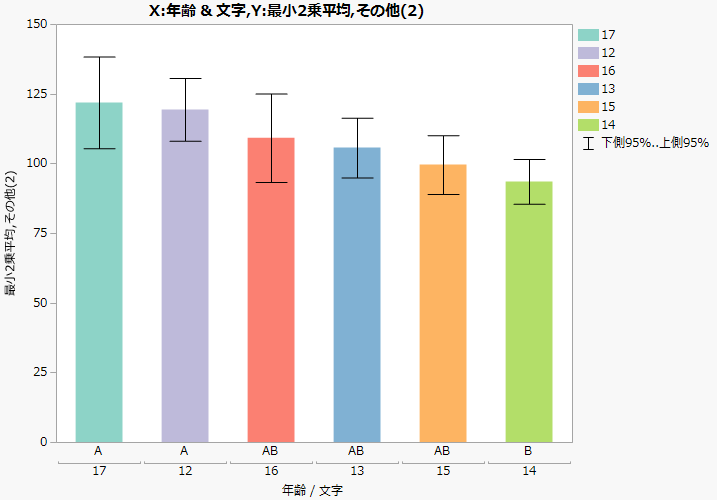
「最小2乗平均差のTukeyのHSD検定」の文字の接続レポートから作成された棒グラフは、「Big Class.jmp」をデータとして用いた棒グラフの例です。この棒グラフを作成するには、まず、データテーブルに添付されている「モデルのあてはめ」スクリプトを実行し、「年齢」の赤い三角ボタンのメニューから[最小2乗平均のTukeyのHSD検定]オプションを選択します。そして、「最小2乗平均差のTukeyのHSD検定」レポートで[文字の接続レポートをテーブルに保存]を選択します。最後に、作成されたデータテーブルで[棒]のスクリプトを実行します。
差、標準誤差、信頼区間、およびp値を差の降順に並べて表示します。また、差を棒グラフで示し、信頼区間を重ねて表示します。
比較ごとに、詳細なレポートを表示します。このレポートには、差の推定値、標準誤差、信頼区間、t値、自由度、および片側および両側検定のp値が表示されます。また、検定結果を視覚化した、t分布の密度曲線も表示されます。この密度曲線の影がついた領域は、両側検定のp値を表します。
Dunnettの検定(Dunnett, 1955)は、各群の平均を、コントロール群(対照群)の平均と比較します。Dunnettの検定では、行われる複数の比較全体に対して、第1種の誤りが制御されています。[最小2乗平均のDunnettの検定]オプションを選択すると、Dunnettの検定が行われます。一般的な状況でのp値と信頼区間の計算には、Hsuの因子分析型近似法が使用されています(Hsu, 1992)。
「最小2乗平均差のDunnettの検定」レポートは、「Cholesterol.jmp」サンプルデータの「処置群」に対して[最小2乗平均のDunnettの検定]オプションを選択したときのレポートです。この例では、応答変数を「6月午後」としています。また、コントロール群は、「処置群」列の「コントロール」です。
図3.18 「最小2乗平均差のDunnettの検定」レポート
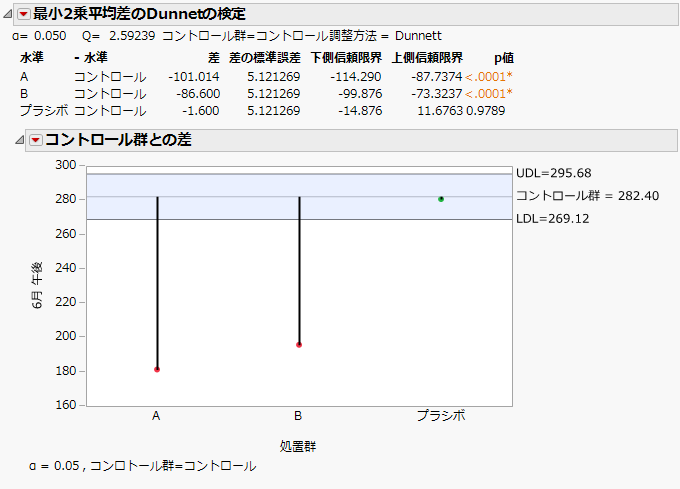
このレポートは、デフォルトで表示されます。効果の各水準に対して、コントロール群と比較した水準、差の推定値、標準誤差、信頼区間、p値といった情報が表示されます。
[検出力の分析]コマンドを選択すると、「検出力の詳細」レポートが開きます。ここで、該当する効果のF検定について、事前や事後の検出力分析を行えます。
メモ: 差を検出するのに必要な標本サイズを、実験や調査を行う前に算出する作業は、 「検出力の事前計算」などと呼ばれています。実験計画は「実験計画(DOE)」プラットフォームで行えますが、 検出力の事前計算には[実験計画(DOE)]>[標本サイズ/検出力]および[実験計画(DOE)]>[計画の評価]が役に立ちます。「モデルのあてはめ」を利用した検出力の事前計算の例については、第 “検出力の事前計算”を参照してください。
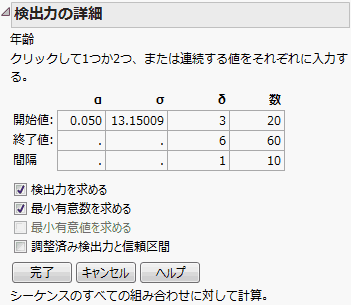
「検出力の詳細」ウィンドウは、「Big Class.jmp」サンプルデータの「検出力の詳細」レポートです。この「検出力の詳細」レポートで、アルファ(α; 有意水準)、シグマ(σ; 誤差の標準偏差)、デルタ(δ; 効果の大きさ)、数(n; 標本サイズ)を入力すると、それらの値に対する検出力が求められます。値を1つだけ(開始値のみ)入力するか、値を2つ(開始値と終了値)入力するか、もしくは、等差数列(開始値、終了値、間隔)で入力してください。入力した値に対して、検出力が計算されます。
図3.19 「検出力の詳細」ウィンドウ
詳細は、第 “検出力の分析”を参照してください。
アルファ(α)
シグマ(σ)
デルタ(δ)
対象となる効果の大きさ(effect size; 効果量)。詳細は、第 “効果の大きさ”の節を参照してください。1行目にあらかじめ入力されている値は、仮説の平方和を標本サイズの平方根で割った値の平方根、つまり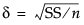 です。
です。
です。数(n)
α、σ、δ、nから、検出力が求められます。検出力とは、指定したσおよびnのとき、有意水準αで検定が有意となり、大きさδの差が検出される確率です。詳細は、付録「統計的詳細」の「検出力の計算」(509ページ)を参照してください。
p値がαとなるパラメータまたはパラメータの線形関数の最小絶対値を求めます。最小有意値は、α、σ、nの関数です。このオプションは、自由度が1の検定に対してだけ使用できます。詳細は、付録「統計的詳細」の「LSVの計算」(508ページ)を参照してください。
検出力を事後的に計算するときは、誤差分散とパラメータに関して、真値ではなく、推定値を使用します。これらの推定値を用いると、F分布の非心度パラメータの推定においてバイアスが生じます。調整済み検出力は、非心度の推定値における正のバイアスを除去するために、計算を調整して検出力を求めたものです(Wright and O’Brien 1988)。
調整済み検出力は、現在のデータから算出された推定値に基づくため、検出力やその信頼区間は、δに対する現在の推定値に対してのみ計算されます。詳細は、付録「統計的詳細」の「調整済み検出力の計算」(510ページ)を参照してください。